September 2019
Intermediate to advanced
217 pages
5h 39m
English
One of the most successful applications of deep learning is something that we carry around with us every day. Whether it’s Siri or Google Now, the engines that power both systems and Amazon’s Alexa are neural networks. In this chapter, we’ll take a look at PyTorch’s torchaudio library. You’ll learn how to use it to construct a pipeline for classifying audio data with a convolutional-based model. After that, I’ll suggest a different approach that will allow you to use some of the tricks you learned for images and obtain good accuracy on the ESC-50 audio dataset.
But first, let’s take a look at sound itself. What is it? How is it often represented in data form, and does that provide us with any clues as to what type of neural net we should use to gain insight from our data?
Sound is created via the vibration of air. All the sounds we hear are combinations of high and low pressure that we often represent in a waveform, like the one in Figure 6-1. In this image, the wave above the origin is high pressure, and the part below is low pressure.
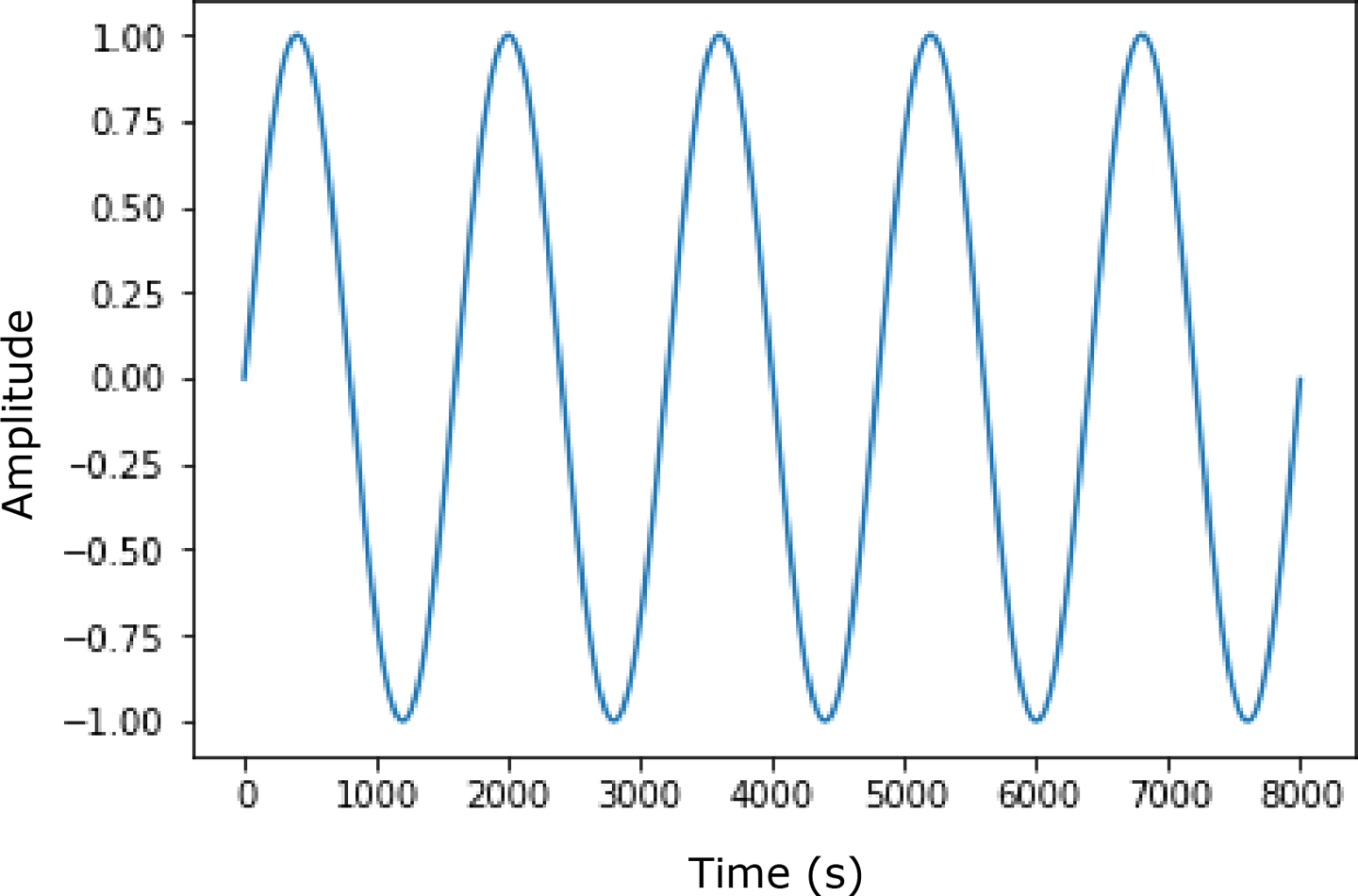
Figure 6-2 shows a more complex waveform of a complete song.
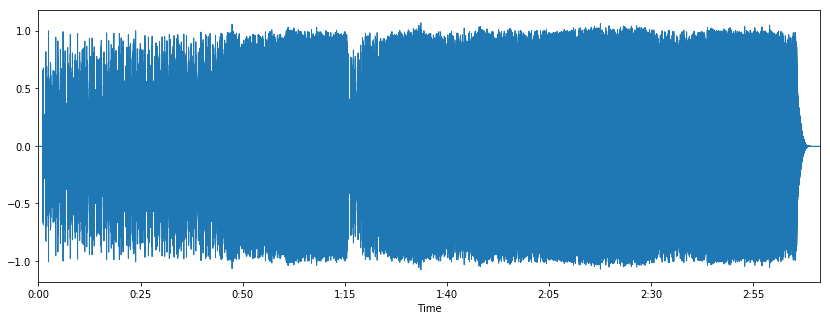
In digital sound, we sample this waveform many times a second, traditionally 44,100 for CD-quality ...