May 2026
Intermediate to advanced
378 pages
8h 17m
English
You can’t improve what you can’t measure. As you tune retrieval parameters, adjust prompts, or switch models, you need metrics that tell you whether changes help or hurt. Without evaluation, optimization becomes guesswork.
RAG evaluation requires different approaches than traditional machine learning (ML). In traditional ML, you train models to learn patterns from labeled data, then test whether they generalize to unseen examples. RAG systems don’t learn—they retrieve and generate. Foundation models already generalize across tasks. The question isn’t whether the model learned patterns, but whether it retrieved the right information and generated useful answers.
This difference shapes how you evaluate. The key challenge is that test questions should cover realistic user intent without appearing word for word in the system’s data, while remaining answerable from the available knowledge. Good generalization in RAG means handling different phrasings of the same underlying question. Intent matters more than exact wording. This affects test design—you reformulate real queries rather than split existing labeled examples.
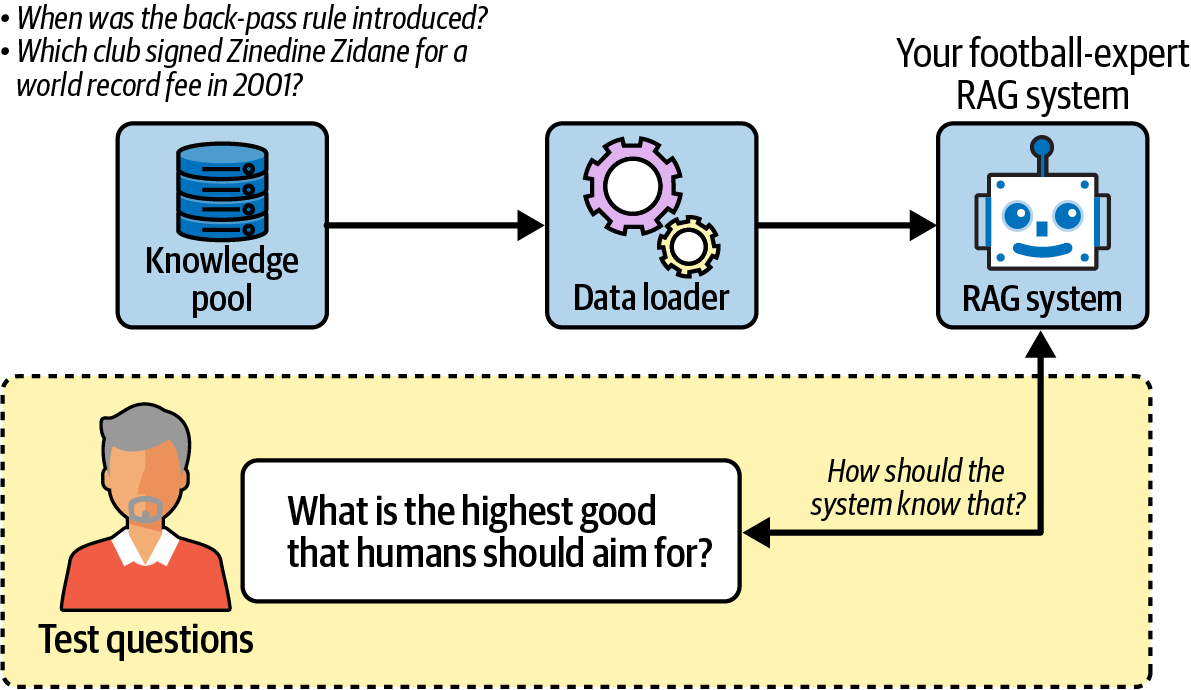
Figure 10-1 illustrates the problem: asking philosophical questions to a system that only knows football (soccer) rules produces meaningless evaluation results.
Read now
Unlock full access






