March 2022
Intermediate to advanced
1136 pages
29h 55m
English
Lookahead policies are based on estimates of the impact of a decision on the future. There are two broad strategies for doing this:
The choice between using value functions versus direct lookaheads boils down to a single equation which gives the optimal policy at time t when we are in state S:
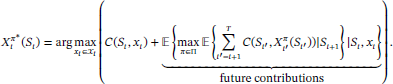 (13.37)
(13.37)The challenge is balancing the contributions now, given by C(St,xt), against future contributions. If we could compute the future contributions, this would be an optimal policy. However, computing future contributions in the presence of a (random) sequential information process is almost always computationally intractable.
There are problems where we can create reasonable approximations of the future contributions. ...
Read now
Unlock full access






