NoSQL is hot. Can NetKernel join in the fray? Yes, it can, and this chapter shows you how easy that is.
The Internet is awash with (often Open Source) initiatives that cover the full range of IT, and beyond. Personally, I love it. When I go browsing without a goal, there is no telling what I will find (another reason for always having a goal upfront). Most such pet projects are short-lived. Some might be interesting, but the available information or documentation is usually so absent that I don’t bother. Now and then, something catches my fancy.
MongoDB caught my eye because it is positioned as a good database backend for a logging application. I wrote one of those (a logging application, that is) myself, and typically these are the issues involved:
Not fast enough
Not flexible enough (schema-wise)
Not flexible enough (search-option-wise)
Here is my personal thought on the first issue: If it is for logging the occasional error you introduce, how fast do you expect it to be when you are sequentially processing a file containing 2 million lines on a 4 quadcore 64 Mb machine? What if, on top of that, you log the whole line and five informational loggings for each line in the file? Oh, and did I mention the 5,000 end users using the same logging application for their online processing? They would like to get some work done today, too. By the way, do you know what the storage on the logging database is going to cost you on a monthly basis?[23]
The flexibility issue is harder to knock down. There are some fixed fields in all loggings, but having those and one big, unmanageable, unindexable, and thus unsearchable message field is not a good solution. And what is the point of having tons of loggings (good question) if you are not able to mine, slice, and dice them?
There are of course solutions to the issues. Most relational databases now have text-indexing and text-search engines (Oracle Text springs to mind). And then there are engines like Lucene (in fact, Lucene is one of the batteries included in NetKernel).
Still, how quickly could I design an interface for MongoDB in NetKernel? Or—to put it less as a pet project of my own—say my company decides tomorrow to move to MongoDB; how quickly am I ready to roll?
This is a book about NetKernel, so I am not going to have an installation guide for MongoDB in it. The website contains all the information, and trust me, you’ll be up and running an instance in five minutes (on Linux or on Windows, you choose); it is that simple.
Warning
All right, all right, just the one hint. A very common (so I’m told) mistake is forgetting that the default location for the database files usually does not exist. You should always first create a location (choose your own) and then start the database as follows:
mongod --dbpath /path/to/location
Note
This chapter has been written with MongoDB release 1.8.2. It has been re-verified for MongoDB release 2.0.1. Intermediate releases should work without a problem as well, but they have not been verified.
Forget Codd for now. It’s all very nice, entities and relationships and normalization, but that does not help a lot when what you want is to store web pages and make them easily retrievable and searchable.
Let us compare a relational database to a document database.
| Relational database | Document database |
|---|---|
| database | database |
| entity | collection |
| record | document |
No, it is not just a matter of different names. A document can be an entire web page, whereas a record (or row) obviously can not. A collection groups documents that are alike (in a very broad sense), whereas an entity (or table) groups records with the exact same structure.
Also, add laziness. If you insert into a nonexisting collection after connecting to a nonexisting database, both database and collection will be created for you as needed. This makes things, as we’ll see, a lot easier.
MongoDB is very JavaScript minded and every installation comes with a JavaScript command-line interface (check the documentation to see how you start it).
Example 4-1. MongoDB in action - 1
MongoDB shell version: 1.8.2 connecting to: test > use loggingdb switched to db loggingdb > db.loggings.insert({ ... 'log':"NETKERNEL", 'logarea':"APPLICATION", ... 'severity':6,'facility':1, ... 'logging':"Started First Module"}) > db.loggings.find() { "_id" : ObjectId("4e0b64dfae7c0689d27b31fb"), "log" : "NETKERNEL", "logarea" : "APPLICATION", "severity" : 6, "facility" : 1, "logging" : "Started First Module"} >
Note
The ellipses are not part of the insert syntax; they are provided by the JavaScript command-line interface to indicate a line continuation.
That wasn’t very hard, was it? You can deduce that I inserted one document (a logging, actually) into the loggings collection of the loggingdb database, and found it again, too. I did not create either database or collection beforehand, and the layout of the document is from my own (relational) logging database.
Now, the network team wants an extra attribute in their loggings (since these always come from a network device). That is possible:
Example 4-2. MongoDB in action - 2
> db.loggings.insert({ ... 'log':"NETWORK",'logarea':"SWITCHES", ... 'severity':6,'facility':1, ... 'logging':"Device rebooted", ... 'device':'evilcoreswitch'}) > db.loggings.find() { "_id" : ObjectId("4e0b64dfae7c0689d27b31fb"), "log" : "NETKERNEL", "logarea" : "APPLICATION", "severity" : 6, "facility" : 1, "logging" : "Started First Module"} { "_id" : ObjectId("4e0b681eae7c0689d27b31fc"), "log" : "NETWORK", "logarea" : "SWITCHES", "severity" : 6, "facility" : 1, "logging" : "Device rebooted", "device" : "evilcoreswitch" } >
And so on and so on. Extensive querying is possible, limited only by your imagination and your JSON (see below) knowledge. From my limited testing, I’d say the flexibility issue moves back from the database to the application. A serious study of MongoDB is definitely on my to-do list.
That, however, is the topic of another book. Right now the goal is to create a MongoDB interface in NetKernel.
Note
JavaScript Object Notation is, like XML, a human-readable data format, closely related to JavaScript. Applications that use JavaScript on the client end will often use it for data handling because it translates into a JavaScript object easily. For NetKernel, JSON is just one of many representation forms that it handles quite happily. MongoDB internally uses BSON (the binary form of JSON), and its interfaces use JSON.
Before getting down to it, let’s state up front what we are going to accomplish: “We are going to build a simple interface that will allow us to do insert, update, delete (remove), and select (find) actions on a MongoDB instance.”
I took the above goal and came up with the following requirements and limitations:[24]
We are building an interface, a library, which will hopefully be used in many other applications. It’s ideal to introduce a second pattern, “The Service Accessor” pattern.[25]
A grammar will handle the requests and pass them on to Groovy-script handlers (one for each action). Yes, I know that I was going to avoid using a lot of different languages, but the MongoDB drivers come in several flavors (DPML not among them), and Groovy is preinstalled in NetKernel (it is extensively used in NetKernel itself, as a complement to Java). So I use the driver from the jar.
Our requests will be simple fire-and-forget requests. By that I mean they will start out stateless, make their own connection, do their thing, clean up their own connection, and return their result.
MongoDB allows for easy replication and high availability. Use of either of those is outside the scope of this module. The database server in the request will look like hostname:portname, for example, localhost:27017, or ip:portname, for example, 192.168.1.10:27017.
Given all that, here’s the module definition I came up with:
Example 4-3. [moduleroot]/module.xml
<?xml version="1.0" encoding="UTF-8"?>
<module version="2.0">
<meta>
<identity>
<uri>urn:org:netkernelbook:chapter4:mongodb</uri>
<version>1.0.0</version>
</identity>
<info>
<name>MongoDB Database Tools</name>
<description>Netkernelbook Chapter 4 MongoDB Database Tools</description>
</info>
</meta>
<system>
<dynamic/>
</system>
<rootspace
name="MongoDB Database Tools"
public="true"
uri="urn:org:netkernelbook:chapter4:mongodb">
<mapper>
<config>
<endpoint>
<id>mongodb:interfaceEP</id>
<name>MongoDB Database Tools - Interface</name>
<description>MongoDB Database Tools - Interface</description>
<grammar>
<active>
<identifier>active:mongodb</identifier>
<argument name="databaseserver" min="1" max="1"
desc="[server:port] combination,
for example localhost:27017"/>
<argument name="databasename" min="1" max="1"
desc="[name] of the database to connect to,
e.g. loggingdb"/>
<argument name="collectionname" min="1" max="1"
desc="[name] of the collection,
e.g. loggings"/>
<argument name="action" min="1" max="1"
desc="[action] to be performed, valid are count,
insert, update, delete, select and drop"/>
<varargs/>
</active>
</grammar>
<request>
<identifier>active:groovy</identifier>
<argument name="operator">
res:/resources/endpoints/mongodb_[[arg:action]].groovy
</argument>
<argument method="as-string" name="databaseserver">
arg:databaseserver
</argument>
<argument method="as-string" name="databasename">
arg:databasename
</argument>
<argument method="as-string" name="collectionname">
arg:collectionname
</argument>
<varargs/>
</request>
</endpoint>
</config>
<space>
<fileset>
<regex>res:/resources/endpoints/mongodb_(insert|update|delete|select|drop).groovy</regex>
<private />
</fileset>
<fileset>
<private />
<regex>res:/lib/.*</regex>
</fileset>
<import>
<private />
<uri>urn:org:netkernel:lang:groovy</uri>
</import>
<import>
<private />
<uri>urn:org:netkernel:json:core</uri>
</import>
</space>
</mapper>
</rootspace>
<rootspace
name="MongoDB Database Tools - Documentation"
public="true"
uri="urn:org:netkernelbook:chapter4:mongodb:documentation">
<fileset>
<regex>res:/etc/system/(Books|Docs).xml</regex>
</fileset>
<fileset>
<regex>res:/resources/documentation/.*</regex>
</fileset>
</rootspace>
<rootspace
name="MongoDB Database Tools - Unit Test"
public="true"
uri="urn:org:netkernelbook:chapter4:mongodb:unittest">
<fileset>
<regex>res:/etc/system/Tests.xml</regex>
</fileset>
<fileset>
<regex>res:/resources/unittest/.*</regex>
</fileset>
<endpoint>
<prototype>Limiter</prototype>
<grammar>res:/etc/
<regex type="anything"/>
</grammar>
</endpoint>
<import>
<uri>urn:org:netkernelbook:chapter4:mongodb</uri>
</import>
<import>
<uri>urn:org:netkernel:lang:groovy</uri>
</import>
<import>
<uri>urn:org:netkernel:json:core</uri>
</import>
<import>
<private/>
<uri>urn:org:netkernel:ext:layer1</uri>
</import>
</rootspace>
</module>The first thing to notice in the [moduleroot]/module.xml file is the absence of a SimpleDynamicImportHook.xml. After a while, you get so used to common “patterns” that you forget what they were for in the first place. Remember that it’s a library we are writing here, a library to be used in other applications. Exposing it to the Frontend (or Backend) HTTPFulcrum is unnecessary and a potential security risk.
As a consequence, we’ll require another application to use this one. But not to worry, the Xunit Test application will do fine. And our [moduleroot]/module.xml has a rootspace for that.
We only have a single entry point, so actually our [moduleroot]/module.xml does not differ all that much from the First Module one. The tricky part is getting the grammar right. Let’s take another look at it:
Example 4-4. Active grammar
<grammar>
<active>
<identifier>active:mongodb</identifier>
<argument name="databaseserver" min="1" max="1"/>
<argument name="databasename" min="1" max="1"/>
<argument name="collectionname" min="1" max="1"/>
<argument name="action" min="1" max="1"/>
<varargs/>
</active>
</grammar>Admit it, that is impressive. But did the above spring from my mind in one piece (like Athena sprang full grown, spear, helmet, and all, from Zeus’s head)?[26]It did not.
At last, here’s another visit to the Backend HTTPFulcrum, and straight to the kitchen, too! Seriously, the Backend HTTPFulcrum is in itself a showcase for NetKernel and contains a number of powerful tools. So why do I not focus on them?
Well, at one point in time, a friend of mine bought a house with a big garden and wanted the trees removed from said garden. So we got ourselves equipped with every imaginable tree cutting/pruning/chopping/sawing tool and went at it. On our first tree (little more than a shoot that had been going strong for a year or four, maybe only three), we spent most of a day, going through four chains on the chainsaw and coming close to destroying a neighbor’s shed as well as losing a limb or two.
We learned every lesson on tree chopping, the hard way. But we were lucky, and a week later, we cut down branches the size of that original shoot from 50-year-old trees in seconds. And they fell (from up to 8 meters high) where we wanted them to fall. We left the big naked trunks for the real professionals. Yes, we learned that lesson, too (basic geometry: if it is 10 meters high standing up, it can reach 10 meters far crashing down).
Before I’m handing you tools, you’ll know what to do with them, and trust me, we’ll cover most of the Backend HTTPFulcrum tools before this book is through. Grammar’s Kitchen[27] is where we are heading now:
Start your favorite web browser.
Browse to http://localhost:1060/tools/grammar.
As you can see, the documentation is on the right. On the left, you can experiment with a grammar, enter an identifier, and check to see if it matches. At the bottom, there’s a Cookbook with a couple of examples. To start our own grammar, select the Simple active URI grammar example (from the Active Grammars submenu). See Figure 4-1.
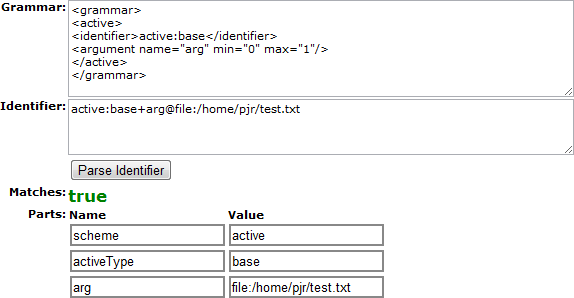
You probably deduced that when you select the Parse Identifier button, the grammar is applied to the identifier. Select it after each step we take so you can see how the grammar is being built up.
Example 4-5. Building our grammar, step 1
Grammar: <grammar> <active> <identifier>active:mongodb</identifier> <argument name="action" min="1" max="1"/> </active> </grammar> Identifier: active:mongodb
Did you select the Parse Identifier button? Then you noticed our identifier did not match the grammar, right? Good! The reason is that we made the action argument mandatory (min="1", max="1"). If we had made it optional (min="0", max="1") our identifier would have worked. Try that! OK? Now, make it mandatory again, and let’s change the identifier.
Let’s add the rest of the mandatory arguments in one go.
Example 4-7. Building our grammar, step 3
Grammar: <grammar> <active> <identifier>active:mongodb</identifier> <argument name="databaseserver" min="1" max="1"/> <argument name="databasename" min="1" max="1"/> <argument name="collectionname" min="1" max="1"/> <argument name="action" min="1" max="1"/> </active> </grammar> Identifier: active:mongodb+action@insert +databaseserver@localhost:27070 +databasename@loggingdb +collectionname@loggings
The above arguments are valid for every type of action. Depending on the action, however, there may be (at least) one or more other arguments. There are two ways to resolve this. Either we specify all possible arguments as optional, or we get lazy (as I did).
Example 4-8. Building our grammar, step 4
Grammar: <grammar> <active> <identifier>active:mongodb</identifier> <argument name="databaseserver" min="1" max="1"/> <argument name="databasename" min="1" max="1"/> <argument name="collectionname" min="1" max="1"/> <argument name="action" min="1" max="1"/> <varargs/> </active> </grammar>
Both the following identifiers will now resolve correctly. Try them yourself (Figure 4-2), and come up with some of your own:
Example 4-9. Building our grammar, step 5
Identifier: active:mongodb+action@insert +databaseserver@localhost:27070 +databasename@loggingdb +collectionname@loggings +docs@[{'log':"NETKERNEL", 'logarea':"APPLICATION", 'severity':5, 'facility':2, 'logging':"Run of MongoDB Multi Insert 1", 'application' : "MongoDB Interface"}, {'log':"NETKERNEL", 'logarea':"APPLICATION", 'severity':5,'facility':2, 'logging':"Run of MongoDB Multi Insert 2", 'application' : "MongoDB Interface"}] Identifier: active:mongodb+action@find +databaseserver@localhost:27070 +databasename@loggingdb +collectionname@loggings +criteria@{} +fields@{}
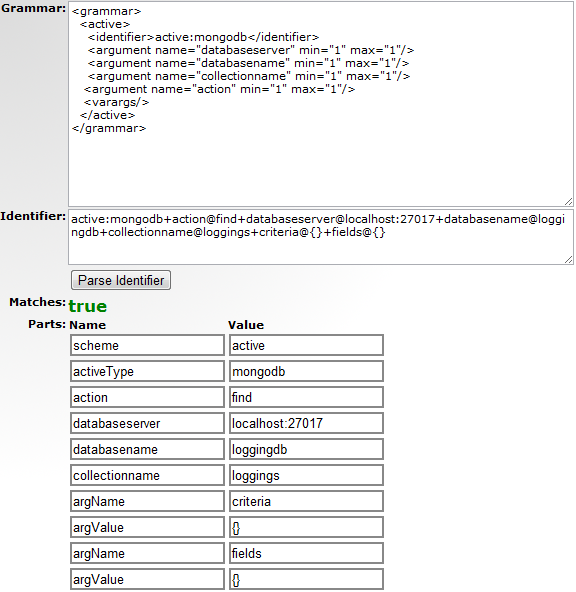
Pretty nifty tool, is it not? You’ll use it quite often. In fact, I use it for something that is not strictly NetKernel related, too.
Example 4-10. Grammar’s Kitchen—RegEx
Grammar: <grammar><regex>[A-Z].{2}[A-Z].{5}</regex></grammar> Identifier: NetKernel
Regular Expressions are a pain in the nether regions, and yet they are everywhere in IT. In Grammar’s Kitchen, you can write them and test them without having to write a single line of code.
With the grammar covered, the request part of our endpoint is pretty straightforward.
Example 4-11. Request
<request>
<identifier>active:groovy</identifier>
<argument name="operator">
res:/resources/endpoints/mongodb_[[arg:action]].groovy
</argument>
<argument method="as-string" name="databaseserver">
arg:databaseserver
</argument>
<argument method="as-string" name="databasename">
arg:databasename
</argument>
<argument method="as-string" name="collectionname">
arg:collectionname
</argument>
<varargs/>
</request>Well, maybe it is not straightforward. There are three ways to add an argument to a request:
As a reference. The operator argument above is an example. We are passing a reference (its URI, as a string) of the resource. Argument substitutions can be used to make this more dynamic.
<argument name="operator"> res:/resources/groovy/mongodb_[[arg:action]].groovy </argument>
As a value. We pass in a literal. No argument substitutions can be used (it’s a literal . . . no substitutions, exchanges, or refunds).
<argument name="logonid"> <literal type="string">mylogonid</literal> </argument>
As a request. The request can itself contain a child request element.
<argument name="logonid"> <request> <identifier>active:determineRandomLogonid</identifier> </request> </argument>
You can probably see the problem. We need to pass values (a database name is not a reference to a resource), but these are not literals. We get them from argument substitution.
By using the method attribute, we can override the default behaviour. The as-string means that we have an incoming pass-by reference (the arguments extracted from our grammar) that we want to turn into a pass-by value. Note that we could also leave the method override out and specify the following (example for database server):
<argument name="databaseserver"> data:text/plain,[[arg:databaseserver]] </argument>
In this way, you do have a reference to a resource, and you can thus use the vanilla way as a reference. Personally, I find the method override to be clearer, but whatever works best for you is fine.
Before tackling the actual Groovy code, we are going to need the MongoDB driver. You can find the java driver at https://github.com/mongodb/mongo-java-driver/archives/master. At the time of this writing, this is mongo-2.6.3.jar. You should drop this in the [moduleroot]/lib directory of your module.
Note
Why put this in the lib subdirectory? Search for classloader in the Backend HTTPFulcrum search tool (http://localhost:1060/tools/search/) and you’ll find (in the first hit) where NetKernel searches for classes (and in what order those locations are visited).
Important
If you’re not finding anything, you might need to (re)build your Search Index first (http://localhost:1060/tools/search/fullIndex).
From the grammar, you can deduce that we are going to have several Groovy programs, one for each action. Let’s start with insert.
Example 4-12. [moduleroot]/resources/endpoints/mongodb_insert.groovy
import com.mongodb.*;
import com.mongodb.util.*;
import org.json.*;
// Prepare the result
jsonResult = new JSONObject();
jsonResult.put("success",true);
jsonResult.put("errors",[]);
jsonResult.put("message",'');
// No errorchecking needed for the following three arguments,
// our grammar takes care of them.
databaseserver = context.source("arg:databaseserver", String.class);
databasename = context.source("arg:databasename", String.class);
collectionname = context.source("arg:collectionname", String.class);
// Get the docs argument. Its either a valid JSONObject or a
// valid JSONArray. Exceptions are caught.
docs = null;
try{
docs = context.source("arg:docs", JSONObject.class);
}
catch(eo){
try{
docs = context.source("arg:docs", JSONArray.class);
}
catch(ea){
jsonResult.putOpt("success",false);
jsonResult.putOpt("message","Argument docs is missing or incorrect");
}
}
if ((docs != null)){
try {
mConnection = new Mongo(databaseserver);
mDatabase = mConnection.getDB(databasename);
mCollection = mDatabase.getCollection(collectionname);
insertresult = mCollection.insert(JSON.parse(docs.toString()));
if (insertresult.getLastError().ok()){
if (insertresult.getError()){
jsonResult.putOpt("success",false);
jsonResult.putOpt("message",insertresult.getError());
}
else {
jsonResult.putOpt("message","Insert is succesful");
}
}
else {
jsonResult.putOpt("success",false);
jsonResult.putOpt("message",
insertresult.getLastError().getErrorMessage());
}
mConnection.close();
}
catch(e){
if (mConnection){
mConnection.close();
}
jsonResult.putOpt("success",false);
jsonResult.putOpt("message","Insert failed on Mongo database");
}
}
response = context.createResponseFrom(jsonResult);
response.setMimeType('application/json');
response.setExpiry(response.EXPIRY_ALWAYS);Nothing special about the above code:
The imports come from the driver jar.
Since JSON is the lingua franca for MongoDB, the response will be a JSONObject.
One extra argument, docs, needs to be handled. It can be a JSONObject (for a single insert) or a JSONArray (for multiple inserts).
The connection to the database is closed before we return the response since we are doing fire-and-forget actions.
The response is immediately expired. I prefer no caching risks with databases (and MongoDB, from what little documentation I read, seems to be vulnerable to those).
The context object is your interface to the ROC world. I didn’t mention this in our First Module. DPML sort of shields you from it. In all other language implementations, you are handed a context object, which hands you full control over your request and full access to your request space (the NKF API, in other words). Don’t worry if you can not see the power of that right now, in our small Groovy action programs, we use the context to get our arguments in and our response out.
Next on the usual-database-action list is an update.
Example 4-13. [moduleroot]/resources/endpoints/mongodb_update.groovy
import com.mongodb.*;
import com.mongodb.util.*;
import org.json.*;
// Prepare the result
jsonResult = new JSONObject();
jsonResult.put("success",true);
jsonResult.put("errors",[]);
jsonResult.put("message",'');
// No errorchecking needed for the following three arguments,
// our grammar takes care of them.
databaseserver = context.source("arg:databaseserver", String.class);
databasename = context.source("arg:databasename", String.class);
collectionname = context.source("arg:collectionname", String.class);
// Get the criteria argument. It has to be a valid JSONObject.
criteria = null;
try{
criteria = context.source("arg:criteria", JSONObject.class);
}
catch(ec){
jsonResult.putOpt("success",false);
jsonResult.putOpt("message",
"Argument criteria is missing or incorrect");
}
// Get the objNew argument. It has to be a valid JSONObject.
objNew = null;
try{
objNew = context.source("arg:objNew", JSONObject.class);
}
catch(eo){
jsonResult.putOpt("success",false);
jsonResult.putOpt("message","Argument objNew is missing or incorrect");
}
// Get the upsert argument. It has to be a valid Boolean.
upsert = null;
try{
upsert = context.source("arg:upsert", Boolean.class);
}
catch(eu){
jsonResult.putOpt("success",false);
jsonResult.putOpt("message","Argument upsert is missing or incorrect");
}
// Get the multi argument. It has to be a valid Boolean.
multi = null;
try{
multi = context.source("arg:multi", Boolean.class);
}
catch(em){
jsonResult.putOpt("success",false);
jsonResult.putOpt("message","Argument multi is missing or incorrect");
}
if ((criteria != null) &&
(objNew != null) &&
(upsert != null) &&
(multi != null)){
try {
mConnection = new Mongo(databaseserver);
mDatabase = mConnection.getDB(databasename);
mCollection = mDatabase.getCollection(collectionname);
updateresult = mCollection.update(JSON.parse(criteria.toString()),
JSON.parse(objNew.toString()),
upsert,
multi);
if (updateresult.getLastError().ok()){
if (updateresult.getError()){
jsonResult.putOpt("success",false);
jsonResult.putOpt("message",updateresult.getError());
}
else {
jsonResult.putOpt("message","Update is succesful");
}
}
else {
jsonResult.putOpt("success",false);
jsonResult.putOpt("message",
updateresult.getLastError().getErrorMessage());
}
mConnection.close();
}
catch(e){
if (mConnection){
mConnection.close();
}
jsonResult.putOpt("success",false);
jsonResult.putOpt("message","Update failed on Mongo database");
}
}
response = context.createResponseFrom(jsonResult);
response.setMimeType('application/json');
response.setExpiry(response.EXPIRY_ALWAYS);A couple more arguments are passed, but otherwise this is almost the same as the insert code. Let’s move on quickly.
Delete is another must-have database action. The MongoDB command is in fact remove.
Example 4-14. [moduleroot]/resources/endpoints/mongodb_delete.groovy
import com.mongodb.*;
import com.mongodb.util.*;
import org.json.*;
// Prepare the result
jsonResult = new JSONObject();
jsonResult.put("success",true);
jsonResult.put("errors",[]);
jsonResult.put("message",'');
// No errorchecking needed for the following three arguments,
// our grammar takes care of them.
databaseserver = context.source("arg:databaseserver", String.class);
databasename = context.source("arg:databasename", String.class);
collectionname = context.source("arg:collectionname", String.class);
// Get the criteria argument. It has to be a valid JSONObject.
criteria = null;
try{
criteria = context.source("arg:criteria", JSONObject.class);
}
catch(ec){
jsonResult.putOpt("success",false);
jsonResult.putOpt("message",
"Argument criteria is missing or incorrect");
}
if ((criteria != null)){
try {
mConnection = new Mongo(databaseserver);
mDatabase = mConnection.getDB(databasename);
mCollection = mDatabase.getCollection(collectionname);
deleteresult = mCollection.remove(JSON.parse(criteria.toString()));
if (deleteresult.getLastError().ok()){
if (deleteresult.getError()){
jsonResult.putOpt("success",false);
jsonResult.putOpt("message",deleteresult.getError());
}
else {
jsonResult.putOpt("message","Delete is succesful");
}
}
else {
jsonResult.putOpt("success",false);
jsonResult.putOpt("message",
deleteresult.getLastError().getErrorMessage());
}
mConnection.close();
}
catch(e){
if (mConnection){
mConnection.close();
}
jsonResult.putOpt("success",false);
jsonResult.putOpt("message","Delete failed on Mongo database");
}
}
response = context.createResponseFrom(jsonResult);
response.setMimeType('application/json');
response.setExpiry(response.EXPIRY_ALWAYS);Oh my, this is getting quite boring, is it not?
Select is the most used database action ever. The MongoDB command is find.
Example 4-15. [moduleroot]/resources/endpoints/mongodb_delete.groovy
import com.mongodb.*;
import com.mongodb.util.*;
import org.json.*;
// Prepare the result
jsonResult = new JSONObject();
jsonResult.put("success",true);
jsonResult.put("errors",[]);
jsonResult.put("message",'');
// No errorchecking needed for the following three arguments,
// our grammar takes care of them.
databaseserver = context.source("arg:databaseserver", String.class);
databasename = context.source("arg:databasename", String.class);
collectionname = context.source("arg:collectionname", String.class);
// Get the criteria argument. It has to be a valid JSONObject.
criteria = null;
try{
criteria = context.source("arg:criteria", JSONObject.class);
}
catch(ec){
jsonResult.putOpt("success",false);
jsonResult.putOpt("message",
"Argument criteria is missing or incorrect");
}
fields = null;
try{
fields = context.source("arg:fields", JSONObject.class);
}
catch(ef){
jsonResult.putOpt("success",false);
jsonResult.putOpt("message","Argument fields is missing or incorrect");
}
// Optional arguments ...
optskip = null;
try{
optskip = context.source("arg:skip", Integer.class);
}
catch(es){
optskip = 0;
}
optlimit = null;
try{
optlimit = context.source("arg:limit", Integer.class);
}
catch(el){
optlimit = 0;
}
optsort = null;
try{
optsort = context.source("arg:sort", JSONObject.class);
}
catch(es){
optsort = new JSONObject();
}
selectresult = null;
if ((criteria != null) &&
(fields != null)){
try {
mConnection = new Mongo(databaseserver);
mDatabase = mConnection.getDB(databasename);
mCollection = mDatabase.getCollection(collectionname);
selectresult = new JSONArray();
selectcursor = mCollection.find(
JSON.parse(criteria.toString()),
JSON.parse(fields.toString())
).sort(JSON.parse(optsort.toString())).skip(optskip).limit(optlimit);
selectcursor.each{
selectresult.put(new JSONObject(it.toString()));
};
mConnection.close();
}
catch(e){
if (mConnection){
mConnection.close();
}
jsonResult.putOpt("success",false);
jsonResult.putOpt("message","The select failed on Mongo database");
}
}
if (selectresult != null){
response = context.createResponseFrom(selectresult);
}
else {
response = context.createResponseFrom(jsonResult);
}
response.setMimeType('application/json');
response.setExpiry(response.EXPIRY_ALWAYS);The code for the select is slightly (only slightly) more complex because it is useless to return whether or not it succeeded. You want to know what it found. Here’s the technical lowdown:
A MongoDB find returns a cursor to the result. We loop through this cursor, appending each result to a JSONArray. The response for a select will therefore always be a JSONArray, unless there is an issue with the database itself (in which case you get a JSONObject returned).
There are five extra arguments here. With criteria, fields, skip, limit, and sort, you can make any query imaginable and do database paging in your application, if you want to.
Not one of the big four database actions, but useful nonetheless, is the drop action. In MongoDB, this drops a collection. It can be very useful if you’ve been experimenting, and since a collection is (re)created lazily at the first insert, there’s no create action needed either.
Example 4-16. [moduleroot]/resources/endpoints/mongodb_drop.groovy
import com.mongodb.*;
import com.mongodb.util.*;
import org.json.*;
// Prepare the result
jsonResult = new JSONObject();
jsonResult.put("success",true);
jsonResult.put("errors",[]);
jsonResult.put("message",'');
// No errorchecking needed for the following three arguments,
// our grammar takes care of them.
databaseserver = context.source("arg:databaseserver", String.class);
databasename = context.source("arg:databasename", String.class);
collectionname = context.source("arg:collectionname", String.class);
try {
mConnection = new Mongo(databaseserver);
mDatabase = mConnection.getDB(databasename);
mCollection = mDatabase.getCollection(collectionname);
mCollection.drop();
jsonResult.putOpt("message","Drop is succesful");
mConnection.close();
}
catch(e){
if (mConnection){
mConnection.close();
}
jsonResult.putOpt("success",false);
jsonResult.putOpt("message","The drop failed on Mongo database");
}
response = context.createResponseFrom(jsonResult);
response.setMimeType('application/json');
response.setExpiry(response.EXPIRY_ALWAYS);This action was not in my original set, but an application I was doing required it. When you want to implement database paging in your application, you’ll need it, too.
Example 4-17. [moduleroot]/resources/endpoints/mongodb_count.groovy
import com.mongodb.*;
import com.mongodb.util.*;
import org.json.*;
// Prepare the result
jsonResult = new JSONObject();
jsonResult.put("success",true);
jsonResult.put("errors",[]);
jsonResult.put("message",'');
// No errorchecking needed for the following three arguments,
// our grammar takes care of them.
databaseserver = context.source("arg:databaseserver", String.class);
databasename = context.source("arg:databasename", String.class);
collectionname = context.source("arg:collectionname", String.class);
// Get the criteria argument. It has to be a valid JSONObject.
criteria = null;
try{
criteria = context.source("arg:criteria", JSONObject.class);
}
catch(ec){
jsonResult.putOpt("success",false);
jsonResult.putOpt("message",
"Argument criteria is missing or incorrect");
}
countresult = null;
if ((criteria != null)){
try {
mConnection = new Mongo(databaseserver);
mDatabase = mConnection.getDB(databasename);
mCollection = mDatabase.getCollection(collectionname);
cursorcount = mCollection.find(
JSON.parse(criteria.toString())
).count();
countresult = new JSONObject();
countresult.put("totalcount",cursorcount);
mConnection.close();
}
catch(e){
if (mConnection){
mConnection.close();
}
jsonResult.putOpt("success",false);
jsonResult.putOpt("message","The count failed on Mongo database");
}
}
if (countresult != null){
response = context.createResponseFrom(countresult);
}
else {
response = context.createResponseFrom(jsonResult);
}
response.setMimeType('application/json');
response.setExpiry(response.EXPIRY_ALWAYS);Are the above six the only possible actions on a MongoDB database? No, but they are the most important. Creating an index was the next one on my list; I leave that one up to you.
Our module is now up and running, but so far you’ve only got my word for it that it does anything at all. Since it is not available on the Frontend HTTPFulcrum, there’s no easy way to test it. Right? Well, actually, there are two ways. Both are in the Backend HTTPFulcrum:
XUnit Testing—http://localhost:1060/test/
Request Resolution trace tool—http://localhost:1060/tools/requesttrace
Note
I’ve put testing in a separate subsection, not because it is something separate, but because I can give it the attention it deserves that way. When you develop an application, writing code and writing tests go hand in glove.
Important
A running MongoDB instance is required for the tests below. I’m running it on the same machine where NetKernel is running, so localhost:27017 is where my database server can be found. Adapt the examples to your configuration where necessary.
Before we get into the details for both, there’s one thing that I have to clear up beforehand. It’s about the optional arguments. Remember that we ensured that the mandatory arguments will all be passed as strings to the request? Well, since we didn’t specify a similar thing for all the optional parameters (because I was lazy, I admit it), we will have to deal with it now. So, if you notice the difference (and you should) between the passing of the mandatory and the optional arguments, the reason is my earlier laziness.
Note
By all means, go back and extend the grammar with all possible optional arguments. Then come back here and remove the extra stuff from the tests that follow.
In order to push our module into XUnit Testing, we require a Tests.xml file.
Example 4-18. [moduleroot]/etc/system/Tests.xml
<?xml version="1.0" encoding="UTF-8"?>
<tests>
<test>
<id>test:urn:org:netkernelbook:chapter4:mongodb</id>
<name>MongoDB Database Tools - Unit Test</name>
<desc>netkernelbook chapter4 mongodb database tools unittest</desc>
<uri>res:/resources/unittest/testlist.xml</uri>
</test>
</tests>This little more than suggests the next file we have to take a look at.
Example 4-19. [moduleroot]/resources/unittest/testlist.xml
<?xml version="1.0" encoding="UTF-8"?>
<testlist>
<assertDefinition name="validMongoDBaction">
<identifier>active:groovy</identifier>
<argument name="operator">
res:/resources/unittest/validMongoDBaction.groovy
</argument>
<argument name="result">arg:test:result</argument>
<argument name="validMongoDBaction">arg:test:tagValue</argument>
</assertDefinition>
<test name="Invoke service by identifier - insert action">
<request>
<identifier>active:mongodb</identifier>
<argument name="databaseserver">localhost:27017</argument>
<argument name="databasename">loggingdb</argument>
<argument name="collectionname">loggings</argument>
<argument name="action">insert</argument>
<argument name="docs">
<literal type="string">
[{'log':"NETKERNEL",
'logarea':"APPLICATION",
'severity':5,
'facility':2,
'logging':"Run of MongoDB Multi Insert 1",
'application' : "MongoDB Interface"
},
{'log':"NETKERNEL",
'logarea':"APPLICATION",
'severity':5,
'facility':2,
'logging':"Run of MongoDB Multi Insert 2",
'application' : "MongoDB Interface"
}
]
</literal>
</argument>
</request>
<assert>
<validMongoDBaction>insert</validMongoDBaction>
</assert>
</test>
<test name="Invoke service by identifier - update action">
<request>
<identifier>active:mongodb</identifier>
<argument name="databaseserver">localhost:27017</argument>
<argument name="databasename">loggingdb</argument>
<argument name="collectionname">loggings</argument>
<argument name="action">update</argument>
<argument name="criteria">
<literal type="string">
{'log':"NETKERNEL"}
</literal>
</argument>
<argument name="objNew">
<literal type="string">
{'$set':{'severity':4}}
</literal>
</argument>
<argument name="upsert">
<literal type="boolean">
false
</literal>
</argument>
<argument name="multi">
<literal type="boolean">
false
</literal>
</argument>
</request>
<assert>
<validMongoDBaction>update</validMongoDBaction>
</assert>
</test>
<test name="Invoke service by identifier - delete action">
<request>
<identifier>active:mongodb</identifier>
<argument name="databaseserver">localhost:27017</argument>
<argument name="databasename">loggingdb</argument>
<argument name="collectionname">loggings</argument>
<argument name="action">delete</argument>
<argument name="criteria">
<literal type="string">
{'severity':4}
</literal>
</argument>
</request>
<assert>
<validMongoDBaction>delete</validMongoDBaction>
</assert>
</test>
<test name="Invoke service by identifier - select action">
<request>
<identifier>active:mongodb</identifier>
<argument name="databaseserver">localhost:27017</argument>
<argument name="databasename">loggingdb</argument>
<argument name="collectionname">loggings</argument>
<argument name="action">select</argument>
<argument name="criteria">
<literal type="string">
{}
</literal>
</argument>
<argument name="fields">
<literal type="string">
{}
</literal>
</argument>
</request>
<assert>
<validMongoDBaction>select</validMongoDBaction>
</assert>
</test>
<test name="Invoke service by identifier - count action">
<request>
<identifier>active:mongodb</identifier>
<argument name="databaseserver">localhost:27017</argument>
<argument name="databasename">loggingdb</argument>
<argument name="collectionname">loggings</argument>
<argument name="action">count</argument>
<argument name="criteria">
<literal type="string">
{}
</literal>
</argument>
</request>
<assert>
<validMongoDBaction>count</validMongoDBaction>
</assert>
</test>
<test name="Invoke service by identifier - drop action">
<request>
<identifier>active:mongodb</identifier>
<argument name="databaseserver">localhost:27017</argument>
<argument name="databasename">loggingdb</argument>
<argument name="collectionname">loggings</argument>
<argument name="action">drop</argument>
</request>
<assert>
<validMongoDBaction>drop</validMongoDBaction>
</assert>
</test>
</testlist>That’s quite a listing or better yet, that’s quite an interesting listing. Each of our MongoDB actions has a test (exactly as it should be if you develop correctly) that can run independently or as a series. The first thing to notice is the construction for the optional arguments:
<argument name="criteria">
<literal type="string">
{'log':"NETKERNEL"}
</literal>
</argument>With the help of the literal tag, we enforce the fact that the data we pass is a value, not a reference, to a resource.
The second thing worthy of study is the fact that I use a custom assert. By all means, read up on the built-in asserts in the documentation, but our MongoDB library returns one of the following:
For a valid select, a JSONArray containing the result set
For a valid select/count, the result is not a status, but the actual data or a number. In all other cases, the result is a status (a JSONObject containing success or failure)
For an valid count, a JSONObject containing a number
While you could certainly construct something with the built-in asserts, I decided to go with a custom assert.
Example 4-20. [moduleroot]/resources/unittest/validMongoDBaction.groovy
import org.json.*;
validMongoDBaction = null;
resultIn = null;
resultOut = true;
try{
validMongoDBaction = context.source("arg:validMongoDBaction")
}
catch(e){
resultOut = false;
}
try{
resultIn = context.source("arg:result")
}
catch(e){
resultOut = false;
}
if ((resultIn != null) &&
(validMongoDBaction != null)){
switch (validMongoDBaction) {
case "insert" :
case "update" :
case "delete" :
case "drop" :
if (resultIn.has("success")){
resultOut = resultIn.getBoolean("success");
}
else {
resultOut = false;
}
break
case "select" :
if (resultIn instanceof JSONArray){
resultOut = true;
// println resultIn.getClass()
}
else{
resultOut = false;
}
break
case "count" :
if (resultIn.has("totalcount")){
resultOut = true;
// println resultIn.getLong("totalcount");
}
else{
resultOut = false;
}
break
default :
resultOut = false;
}
}
response = context.createResponseFrom(resultOut);
response.setMimeType('text/plain');
response.setExpiry(response.EXPIRY_ALWAYS);Our custom assert is written in Groovy and manipulates JSONArrays and JSONObjects. In order to make this work, our unit test rootspace requires two imports that you may have wondered about.
<import> <uri>urn:org:netkernel:lang:groovy</uri> </import> <import> <uri>urn:org:netkernel:json:core</uri> </import>
If you perform the tests one by one and check the MongoDB database (with the default client) in between, you’ll be able to follow along. Still, it’s pretty boring to have to do tests in order to actually do something on that database, no?
The Request Resolution Trace Tool comes to your rescue (see Figure 4-3)!
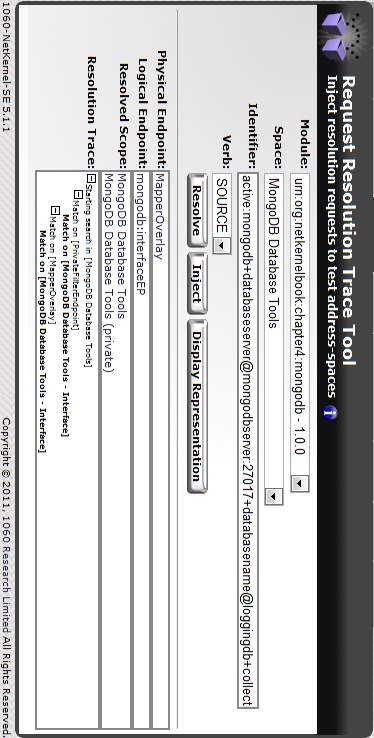
This is a very powerful tool. It allows you to check the resolution of a request against a specific space. Let’s see what the following identifier can teach us about it.
active:mongodb +databaseserver@localhost:27017 +databasename@loggingdb +collectionname@loggings +action@drop
Important
The whole identifier has to be specified on one line, something that is rather impossible in a book.
You can see the result of a Resolve in Figure 4-4 and how an Inject actually executes the request in Figure 4-5.
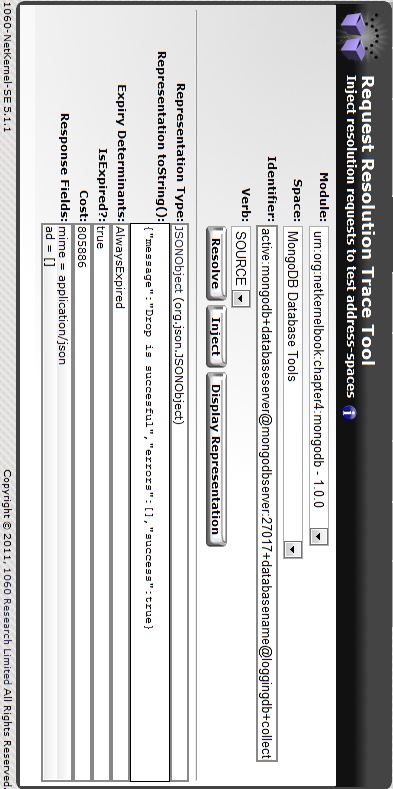
Right, that should keep you happy for a while. Make sure to do a couple of inserts, experiment with the selects, and when you want to clean up the mess after your joyride, do a drop.
In order to push our module into the Documentation application, we require a Books.xml and a Docs.xml file.
Note
Just like you should write tests while you are developing, you should write documentation while you are developing, not afterwards.
Example 4-21. [moduleroot]/etc/system/Books.xml
<?xml version="1.0" encoding="UTF-8"?>
<books>
<book>
<id>book:urn:org:netkernelbook:chapter4:mongodb</id>
<title>MongoDB Database Tools</title>
<desc>netkernelbook chapter4 mongodb database tools documentation</desc>
<toc>
<item
id="urn:org:netkernelbook:chapter4:mongodb:guide"/>
<item
id="urn:org:netkernelbook:chapter4:mongodb:interfacereference"/>
</toc>
</book>
</books>Example 4-22. [moduleroot]/etc/system/Docs.xml
<?xml version="1.0" encoding="UTF-8"?>
<docs>
<doc>
<id>urn:org:netkernelbook:chapter4:mongodb:guide</id>
<title>Introduction to MongoDB</title>
<desc>mongodb introduction</desc>
<uri>res:/resources/documentation/doc_mongodb_introduction.txt</uri>
</doc>
<doc>
<id>urn:org:netkernelbook:chapter4:mongodb:interfacereference</id>
<title>Reference for MongoDB Interface</title>
<desc>mongodb interface reference</desc>
<uri>res:/resources/documentation/doc_mongodb_interface.txt</uri>
</doc>
</docs>So, we are going to have one book with two documents, a general introduction to MongoDB, and a reference to the MongoDB interface we developed. The funny thing is that the second document is practically going to write itself.
Example 4-23. [moduleroot]/resources/documentation/doc_mongodb_interface.txt
{endpoint}mongodb:interfaceEP{/endpoint}One line—it’s just one single line! Have a look at it: http://localhost:1060/books/?filter=mongodb. Is that cool or what? With very little effort during development, documentation is available and easy to maintain. Just one file remains to complete our documentation now.
Example 4-24. [moduleroot]/resources/documentation/doc_mongodb_introduction.txt
== Documentation Stub == This is a documentation stub. For more information on editing documentation see the [doc:sysadmin:guide:doc:editing|Editing Guide].
Yes, it’s just a documentation stub. Don’t you think I’ve blown the MongoDB trumpet hard enough already? You’ll find all the information you need on the MongoDB website.
As you can see, it is not all that hard to bridge the gap between NetKernel and the following:
Any third party code you want to try out
Your company’s current code
Other possibilities
In my personal experience, I’ve approached this in two ways:
Use the code as a NetKernel resource
Use the data provided by the code as a NetKernel resource
The first option is preferred; the second is, however, an easier way to lower the resistance to change in your company.
There is major room for improvement here. Let’s touch on one thing that would almost certainly be needed on the road toward the real integration (rather than just interfacing) of the MongoDB library. Take into account the actions on the documents in our database, and then we’ll discuss verbs (that is, actions on resources).
- SOURCE
Retrieve a representation of the identified resource.
- SINK
Update the resource to reflect the information contained in the primary representation.
- EXISTS
Test to see if a resource identifier can be resolved and the resource exists.
- DELETE
Remove the resource from the space which currently contains it, and return the value TRUE if successful or FALSE if not successful.
- NEW
Create a new resource and return an identifier for the created resource. If a primary representation is included in the request, use it to initialize the state of the resource.
Search http://localhost:1060/tools/search/ with the keyword verbs: the top hit contains all possible verbs, as well as the correct definition of a verb. Even without that information, you’ll probably already agree that I didn’t do ROC justice by using the default verb (SOURCE) for all my MongoDB requests. The above verbs and their definitions match the database actions perfectly.
So, if you feel like a challenge at this point, make a version 2.0.0 of the module that does do justice to ROC!
The download for this chapter can be found here.
[23] Forgive me the rant.
[24] The limitations are not due to NetKernel, they are due to me wanting to keep this section within limits.
[25] The first one was “The Web Server” pattern.
[26] This happened in Greek mythology. Afterward, Zeus became the lead singer for Fischer-Z (hence the Z) and wrote the song “Pretty Paracetamol,” or something along those lines.
[27] Nothing to do with Gordon Ramsay (if that name does not ring a bell . . . keep it that way), it’s a pun on Grandma’s Kitchen.
Get Resource-Oriented Computing with NetKernel now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

