March 2025
Beginner to intermediate
220 pages
3h 15m
Japanese
この作品はAIを使って翻訳されている。ご意見、ご感想をお待ちしている:translation-feedback@oreilly.com
AATDは現在、注文数や売上高をリアルタイムで把握できていない。 同社は、注文数の急増や減少を把握することで、演算子により迅速に対応できるようにしたいと考えている。
AATDのエンジニアリング・チームは、既に他のアプリケーションでKafka Streamsに慣れているので、最近の注文と収益を表示するHTTPエンドポイントを公開するKafka Streamsアプリを作成する。 Quarkusフレームワークを使ってこのアプリを作成し、まずは素朴なバージョンから始める。その後、いくつかの最適化を適用する。最後に、ストリーム・プロセッサを使用してストリーミング・データをクエリすることの限界について要約する。図 4-1に、この章で構築するものを示す。
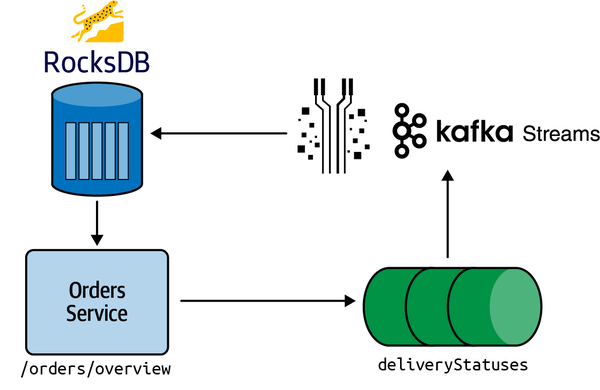
Kafka Streamsは、入力Kafkaトピックを出力Kafkaトピックに変換するストリーミング・アプリケーションを構築するためのライブラリである 。第2章で説明したリアルタイム分析スタックのストリーム・プロセッサ・コンポーネントの一例である。
Kafka Streamsは、ストリームの結合、フィルタリング、変換によく使われるが、この章では既存のストリームをクエリするために使う。
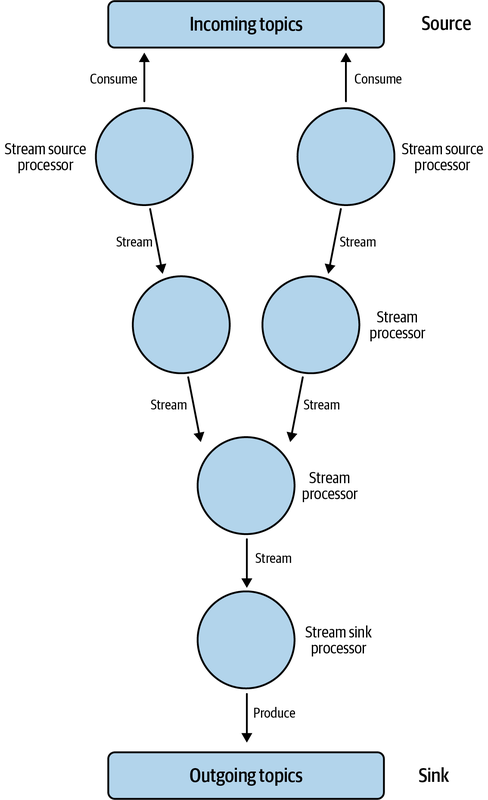
Kafka Streams アプリケーションの中心は、アプリケーションのストリーム処理ロジックを定義するトポロジーである。 トポロジーは、データが入力ストリーム(ソース)からどのように消費され、出力ストリーム(シンク)にプロデューサを生成できるように変換されるかを記述する。
具体的には、『The Internals of Kafka Streams』の著者であるJacek Laskowski氏は、トポロジーを以下のように定義している:
Kafka Streamsアプリケーションのストリーム処理ロジックを表す、ストリーム処理ノードの有向非循環グラフ。
このグラフでは、ノードは処理作業であり、関係はストリームである。 このトポロジーを通じて、最も複雑なデータ処理タスクも処理できる強力なストリーミング・アプリケーションを作成することができる。図4-2にトポロジーの例を示す。
Kafka Streamsはドメイン固有言語(DSL)を提供し、 これらのトポロジーの構築を簡素化する。
このセクションで使用するKafka Streamsの抽象化の定義を説明しよう。 以下の定義は公式ドキュメントから引用している:
KStreamは、 レコードストリームの抽象化であり、各データレコードは、束縛されていないデータセット内の自己完結したデータを表す。 KStream内のデータレコードは「INSERT」操作として解釈され、各レコードは、追記のみの元帳に新しいエントリを追加する。 ...