March 2020
Beginner to intermediate
417 pages
11h 9m
English
When you use DataStax Graph, you are working with graph data in Cassandra. And if you have been following along and executing the implementation details from the last two chapters, you have already been using it.
The paradigm shift from working with a traditional database to working with Apache Cassandra is that we write our data according to how we are going to read it.
To illustrate how we apply this, the examples in Chapters 3 and 4 used but skipped over fundamental topics of working with graph data in Apache Cassandra. Concepts like edge direction and partition key design are fundamental to building a production-quality, scalable, and distributed graph data model.
We are going to dig deeply into the topics of distributed data to set you up for a successful use of distributed graph technology within your production stack.
Recall that we mentioned at the end of Chapter 4 that we purposely set up some traps. Our example built up the schema shown in Figure 5-1 and aimed to use queries like we have in Example 5-1.
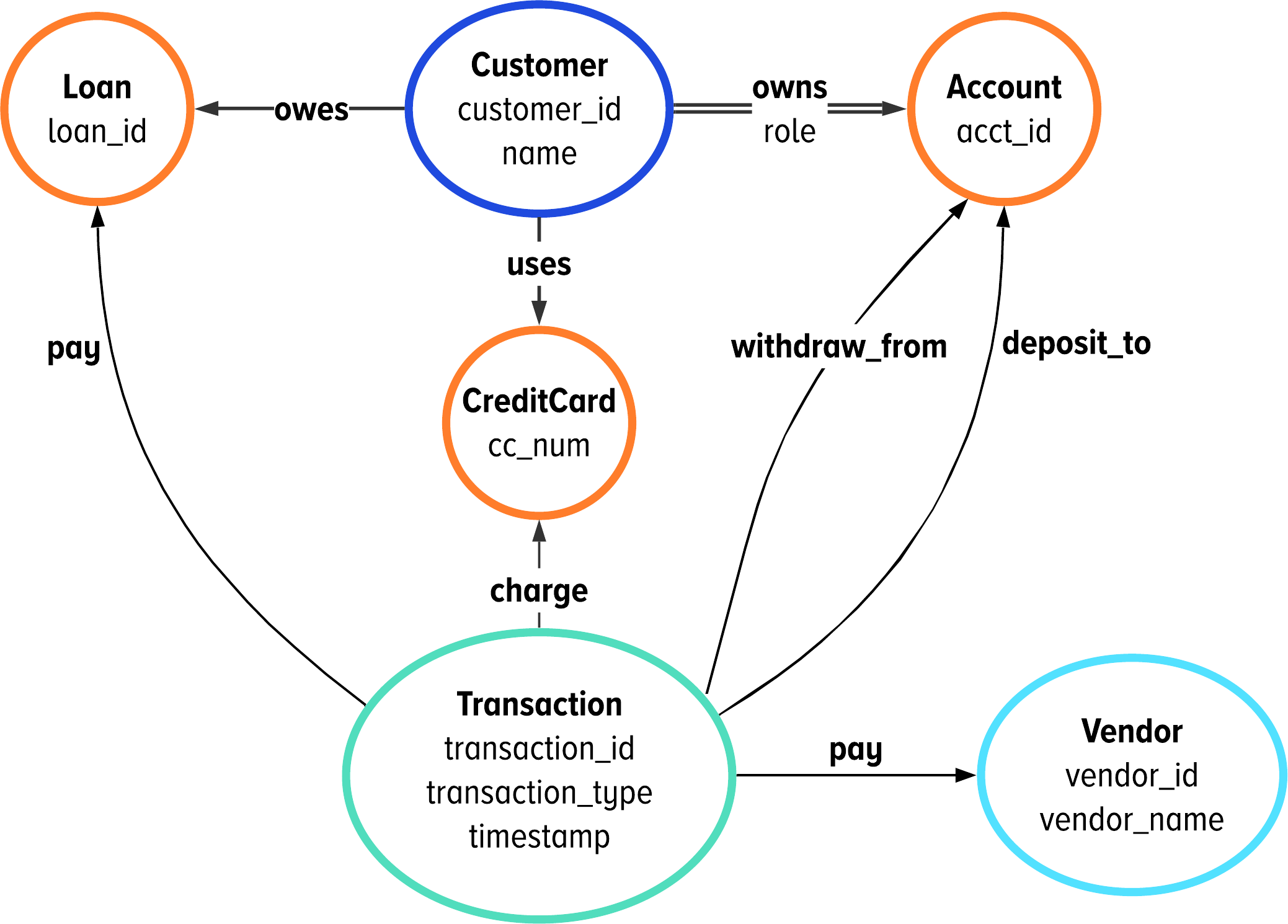
We need to connect two concepts together so you can see the whole picture. First, all of our queries have used the development traversal source dev.V(). The development traversal source in DataStax ...
Read now
Unlock full access






