Letâs look at how Gitâs objects fit and work together to form the complete system.
The blob object is at the âbottomâ of the data structure; it references nothing and is referenced only by tree objects. In the figures that follow, each blob is represented by a rectangle.
Tree objects point to blobs, and possibly to other trees as well. Any given tree object might be pointed at by many different commit objects. Each tree is represented by a triangle.
A circle represents a commit. A commit points to one particular tree that is introduced into the repository by the commit.
Each tag is represented by a parallelogram. Each tag can point to at most one commit.
The branch is not a fundamental Git object, yet it plays a crucial role in naming commits. Each branch is pictured as a rounded rectangle.
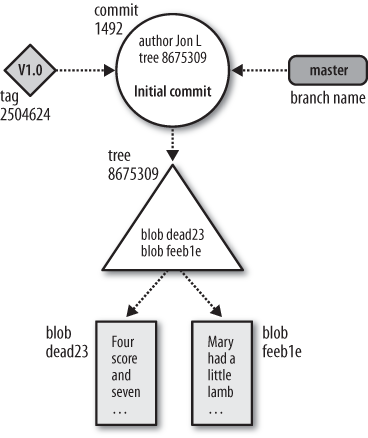
Figure 4-1 captures how all the pieces fit
together. This diagram shows the state of a repository after a single,
initial commit added two files. Both files are in the top-level
directory. Both the master branch and a tag named
V1.0 point to the commit with ID
8675309.
Now, letâs make things a bit more complicated. Letâs leave the original two files as is, adding a new subdirectory with one file in it. The resulting object store looks like Figure 4-2.
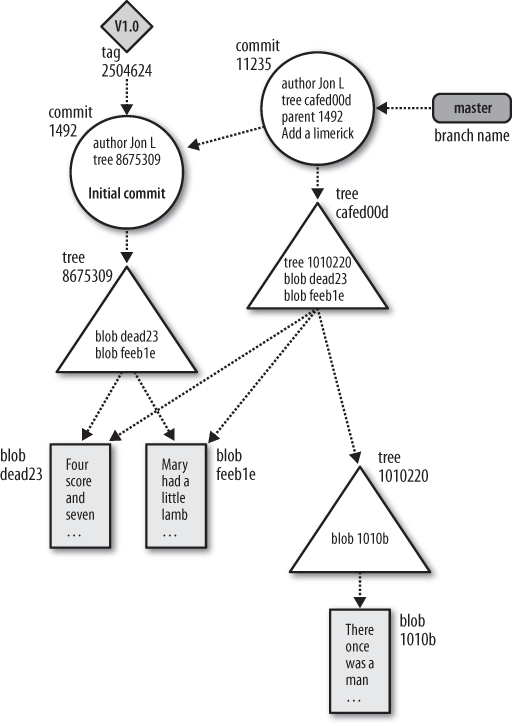
As in the previous picture, the new commit has added one
associated tree object to represent the total state of directory and
file structure. In this case, it is the tree object with ID
cafed00d.
Since the top-level directory is changed by the addition of the
new subdirectory, the content of the top-level tree
object has changed as well, so Git introduces a new tree,
cafed00d.
However, the blobs dead23 and
feeb1e didnât change from the first commit to the
second. Git realizes that the IDs havenât changed and thus can be
directly referenced and shared by the new cafed00d
tree.
Pay attention to the direction of the arrows between commits. The parent commit or commits come earlier in time. Therefore, in Gitâs implementation, each commit points back to its parent or parents. Many people get confused because the state of a repository is conventionally portrayed in the opposite direction: as a dataflow from the parent commit to child commits.
In Chapter 6, we extend these pictures to show how the history of a repository is built up and manipulated by various commands.
Get Version Control with Git now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

