Chapter 1.
Introduction
So what does Web client programming mean, and what do you need to learn to do it?
A web client is an application that communicates with a web server, using Hypertext Transfer Protocol (HTTP). Hypertext Transfer Protocol is the protocol behind the World Wide Web. With every web transaction, HTTP is invoked. HTTP is behind every request for a web document or graphic, every click of a hypertext link, and every submission of a form. The Web is about distributing information over the Internet, and HTTP is the protocol used to do so.
Most web users never think about HTTP, just as most TV viewers don't think about how video images get from the studio to their home. But this book is not for the average web user. This book is for people who want to do something that available web software won't let them do.
Why Write Your Own Clients?
With the proliferation of available web browsers, you might wonder why you would want to write your own client program. The answer is that by writing your own client programs, you can leap beyond the preprogrammed functionality of a browser. For example, the following scenarios are all possible:
- An urgent document is sent out via Federal Express, and the sender wants to know the status of the document the moment it becomes available. He enters the FedEx airbill tracking number into a program that notifies him of events as the FedEx server reports them. Since the document is urgent, he configures the program to contact him if the document is not delivered by the next morning.
- A system administrator would like to verify that all hyperlinks and image references are valid at her site. She runs a program to verify all documents at the site and report the results. She then finds some common mistakes in numerous documents, and runs another program to automatically fix them.
- An investor keeps a stock portfolio online and runs a program to check stock prices. The online portfolio is updated automatically as prices change, and the program can notify the investor when there is an unusual jump in a stock price.
- A college student connects his computer to the Internet via an Ethernet connection in his room. The university distributes custom software that will allow his computer to wake him up every morning with local news. Audio clips are downloaded and a web browser is launched. As the sound clips play, the browser automatically updates to display a new image that corresponds to the report. A weather map is displayed when the local weather is being announced. Images of the campus are displayed as local news is announced. National and international news briefs are presented in this automatic fashion, and the program can be configured to omit and include certain topics. The student may flunk biology, but at least he'll be the first to know who won the Bulls game.
And so on. Think about resources that you regularly visit on the Web. Maybe every morning you check the David Letterman top ten list from last night, and before you leave the office you check the weather report. Can you automate those visits? Think about that time you wanted to print an entire document that had been split up into individual files, and had to select Chapter 1, print, return to the contents page, select Chapter 2, etc. Is there a way to print the entire thing in one swoop?
Browsers are for browsing. They are wonderful tools for discovery, for traveling to far-off virtual lands. But once you know what you want, a more specialized client might be more effective for your needs.
The Web and HTTP
If you don't know what the Web is, you probably picked up the wrong book. But here's some history and background, just to make sure we're all coming from the same place.
The World Wide Web was developed in 1990 by Tim Berners-Lee at the Conseil Europeen pour la Recherche Nucleaire (CERN). The inspiration behind it was simply to find a way to share results of experiments in high-energy particle physics. The central technology behind the Web was the ability to link from a document on one server to a document on another, keeping the actual location and access method of the documents invisible to the user. Certainly not the sort of thing that you'd expect to start a media circus.
So what did start the media circus? In 1993 a graphical interface to the Web, named Mosaic, was developed at the University of Illinois at Urbana-Champaign. At first, Mosaic ran only on UNIX systems running the X Window System, a platform that was popular with academics but unknown to practically anyone else. Yet anyone who saw Mosaic in action knew immediately that this was big news. Soon afterwards, Mac and PC versions came out, and the Web started to become immensely popular. Suddenly the buzzwords started proliferating: Information Superhighway, Internet, the Web, Mosaic, etc. (For a while all these words were used interchangeably, much to the chagrin of anyone who had been using the Internet for years.)
In 1994, a new interface to the Web called Netscape Navigator came on the (free) market, and quickly became the darling of the Net. Meanwhile, everyone and their Big Blue Brother started developing their own web sites, with no one quite sure what the Web was best used for, but convinced that they couldn't be left behind.
Most of the confusion has died down now, but not the excitement. The Web seems to have permanently captured the imagination of the world. It brings up visions of vast archives that can now be made globally available from every desktop, images and multimedia that can be distributed to every home, and... money, money, money. But the soul of the Web is pure and unchanged. When you get down to it, it's just about sending data from one machine to another--and that's what HTTP is for.
Browsers and URLs
The most common interface to the World Wide Web is a browser, such as Mosaic, Netscape Navigator, or Internet Explorer. With a browser, you can download web documents and view them formatted on your screen.
When you request a document with your browser, you supply a web address, known as a Universal Resource Locator or URL. The URL identifies the machine that contains the document you want, and the pathname to that document on the server. The browser contacts the remote machine and requests the document you specified. After receiving the document, it formats it as needed and displays it on your browser.
For example, you might click on a hyperlink corresponding to the URL http://www.oreilly.com/index.html. Your browser contacts the machine called www.oreilly.com and requests the document called index.html. When the document arrives, the browser formats it and displays it on the screen. If the document requires other documents to be retrieved (for example, if it includes a graphic image on the page), the browser downloads them as well. But as far as you're concerned, you just clicked on a word and a new page appeared.
Clients and Servers
Your web browser is an example of a web client. The remote machine containing the document you requested is called a web server. The client and server communicate using a special language (a “protocol”) called HTTP. Figure 1-1 demonstrates the relationship between web clients and web servers.
Figure 1-1.
Client and server relationship
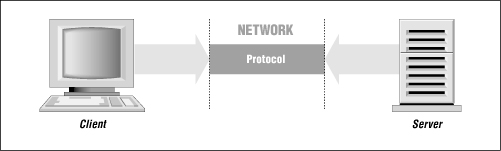
To keep ourselves honest, we should get a little more specific now. Although we commonly refer to the machine that contains the documents as the “server,” the server isn't the hardware itself, but just a program that runs on that machine. The web server listens on a port on the network, and waits for client requests using the HTTP protocol. After the server responds to the request (using HTTP), the network connection is dropped and the browser processes the relevant data that it received, then displays it on your screen.
In practice, many clients can be using the same server at the same time, and one client can also use many servers at the same time (see Figure 1-2).
Figure 1-2.
Multiple clients and servers
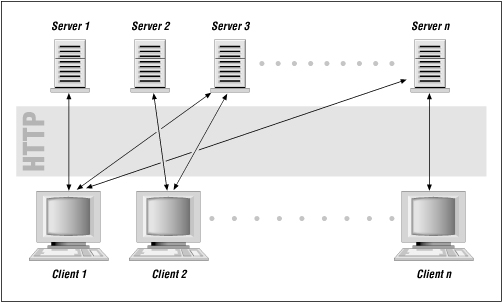
As you can see, at the core of the Web is HTTP. If you master HTTP, you can request documents from a server without needing to go through your browser. Similarly, you can return documents to web browsers without being limited to the functionality of an existing web server. HTTP programming takes you out of the realm of the everyday web user and into the world of the web power user.
Chapter 2, Demystifying the Browser, introduces you to simple HTTP as commonly encountered on the Web. Chapter 3, Learning HTTP, is a more complete reference on HTTP.
The Programming Interface
Okay, we've told you a little about HTTP. But before your client can actually communicate with a server, it needs to establish a connection. It's like having a VCR and a TV, but no cable between them.
TCP/IP is what makes it possible for web clients and servers to speak to each other using HTTP. TCP/IP is the protocol used to send data packets across the Internet uncorrupted. Programmers need a TCP/IP programming interface, like Berkeley sockets, for their web programs to communicate.
Now, this is when we separate our audience into the lucky and the . . . less lucky.
One of the great virtues for which Perl programmers are extolled is laziness. The Perl community encourages programmers to develop modules and libraries that perform common tasks, and then to share these developments with the world at large. While you can write Perl programs that use sockets to contact the web server and then send raw HTTP requests manually, you can also use a library for Perl 5 called LWP (Library for WWW access in Perl), which basically does all the hard work for you.
Great news, huh? Only for those of us on UNIX, though. At this writing, LWP has not been fully ported to Windows 95 or Windows NT, and using Perl's socket library under NT isn't quite the same. There are some great developments from vendors like ActiveWare and Softway that might one day make NT's Perl environment look exactly as it does on UNIX. For now, however, NT users have to cope with what's out there. But on the brighter side, NT's Perl environment is getting better over time.
Also, some readers may be stuck with Perl 4, in which case LWP is off limits. Many Internet Service Providers do not support software “extras” like Perl, and thus will not upgrade the version of Perl 4 that was distributed with their operating system. Perl 4 is considered unsupported and buggy by most Perl experts, but for many readers, it's all they have.
Chapter 4, The Socket Library, covers sockets, and Chapter 5, The LWP Library, introduces you to LWP. Since most Perl programmers have LWP available to them, we wrote all the examples in Chapters See Example LWP Programs and using LWP. However, Chapter 4 does show some examples of writing simple clients using Sockets, for those readers who cannot use LWP (or choose not to).
A Word of Caution
There are some dangers in developing and configuring Web client programs. A buggy client program may overload a web server. It could cause massive amounts of network traffic. Or you might receive flame mail or lawsuits from web maintainers. Worst of all, web clients could cause data integrity problems on servers by feeding bad data to Common Gateway Interface (CGI) programs that don't bother to check for proper input. To avoid these disasters, there are a few things you can do:
- Test your code locally. The ideal environment for web development is a machine running both the web client and the web server. When you use this type of setup, communication between the client and server doesn't actually go though a network connection. Instead, communication is done locally by the operating system. If the computer dramatically slows down shortly after running your newly written client, you know there's a problem. Such a program would be even slower over a network.
- Run your own server. Many excellent servers are freely available on the Internet, and it is far better to accidentally overload your own server than the one used by your Internet Service Provider (ISP) or company.
- Give yourself options. When you finally decide to run your client program with someone else's server, leave your “verbose” options on and watch what your program is doing. Make sure you designed your program so you can stop it if it is getting out of hand.
- Ask permission. Some servers are not intended to be queried by custom-made web clients. Ask the maintainers of the server if you can run your client on their server.
- Most importantly, follow the Robot Exclusion Standard at http://info.webcrawler.com/mak/projects/robots/norobots. (See Appendix C for more information on the Robot Exclusion Standard.)
Basically, a home-grown web client is like an uninvited guest, and like all gate crashers, you should be polite and try not to draw too much attention to yourself. If you guzzle down all the good liquor and make a nuisance of yourself, you will be asked to leave.
Get Web Client Programming with Perl now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

