Got speech? These guidelines will help you get started building voice applications
Speech adds another level of complexity to AI applications—today’s voice applications provide a very early glimpse of what is to come.
 Soundwave circle (source: PublicDomainPictures.net)
Soundwave circle (source: PublicDomainPictures.net)
As companies begin to explore AI technologies, three areas in particular are garnering a lot of attention: computer vision, natural language applications, and speech technologies. A recent report from the World Intellectual Patent Office (WIPO) found that together these three areas accounted for a majority of patents related to AI: computer vision (49% of all patents), natural language processing (NLP) (14%), and speech (13%).
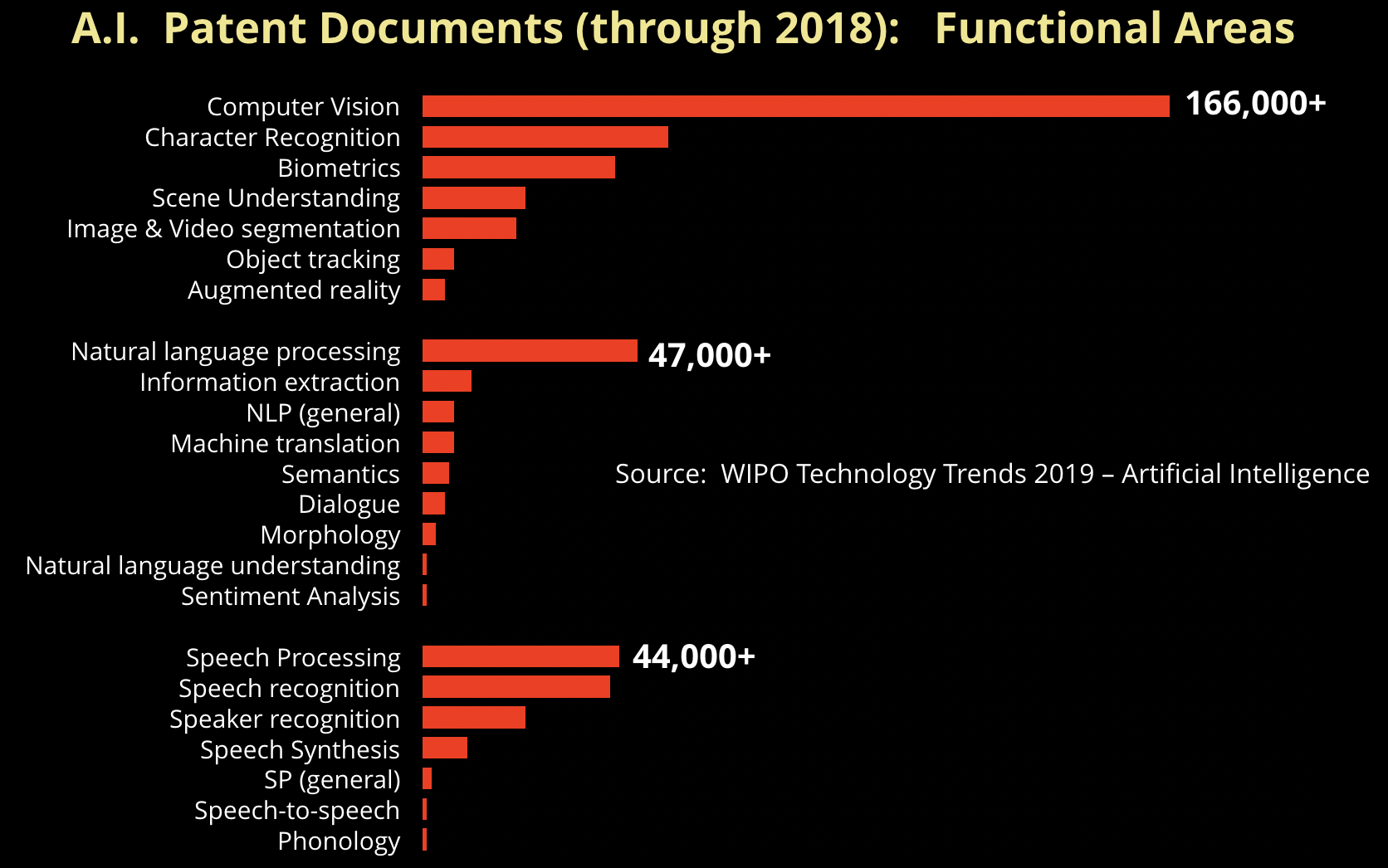
Companies are awash with unstructured and semi-structured text, and many organizations already have some experience with NLP and text analytics. While fewer companies have infrastructure for collecting and storing images or video, computer vision is an area that many companies are beginning to explore. The rise of deep learning and other techniques have led to startups commercializing computer vision applications in security and compliance, media and advertising, and content creation.

Learn faster. Dig deeper. See farther.
Companies are also exploring speech and voice applications. Recent progress in natural language and speech models have increased accuracy and opened up new applications. Contact centers, sales and customer support, and personal assistants lead the way as far as enterprise speech applications. Voice search, smart speakers, and digital assistants are increasingly prevalent on the consumer side. While far from perfect, the current generation of speech and voice applications work well enough to drive an explosion in voice applications. An early sign of the potential of speech technologies is the growth of voice-driven searches: Comscore estimates that by 2020 about half of all online searches will use voice; Gartner recommends that companies redesign their websites to support both visual and voice search. Additionally, smart speakers are projected to grow by more than 82% from 2018 to 2019, and by the end of the year, the installed base for such devices will exceed 200 million.
Audio content is also exploding, and this new content will need to be searched, mined, and unlocked using speech technologies. For example, according to a recent New York Times article, in the US, “nearly one out of three people listen to at least one podcast every month.” The growth in podcasts isn’t limited to the US: podcasts are growing in other parts of the world, including China.
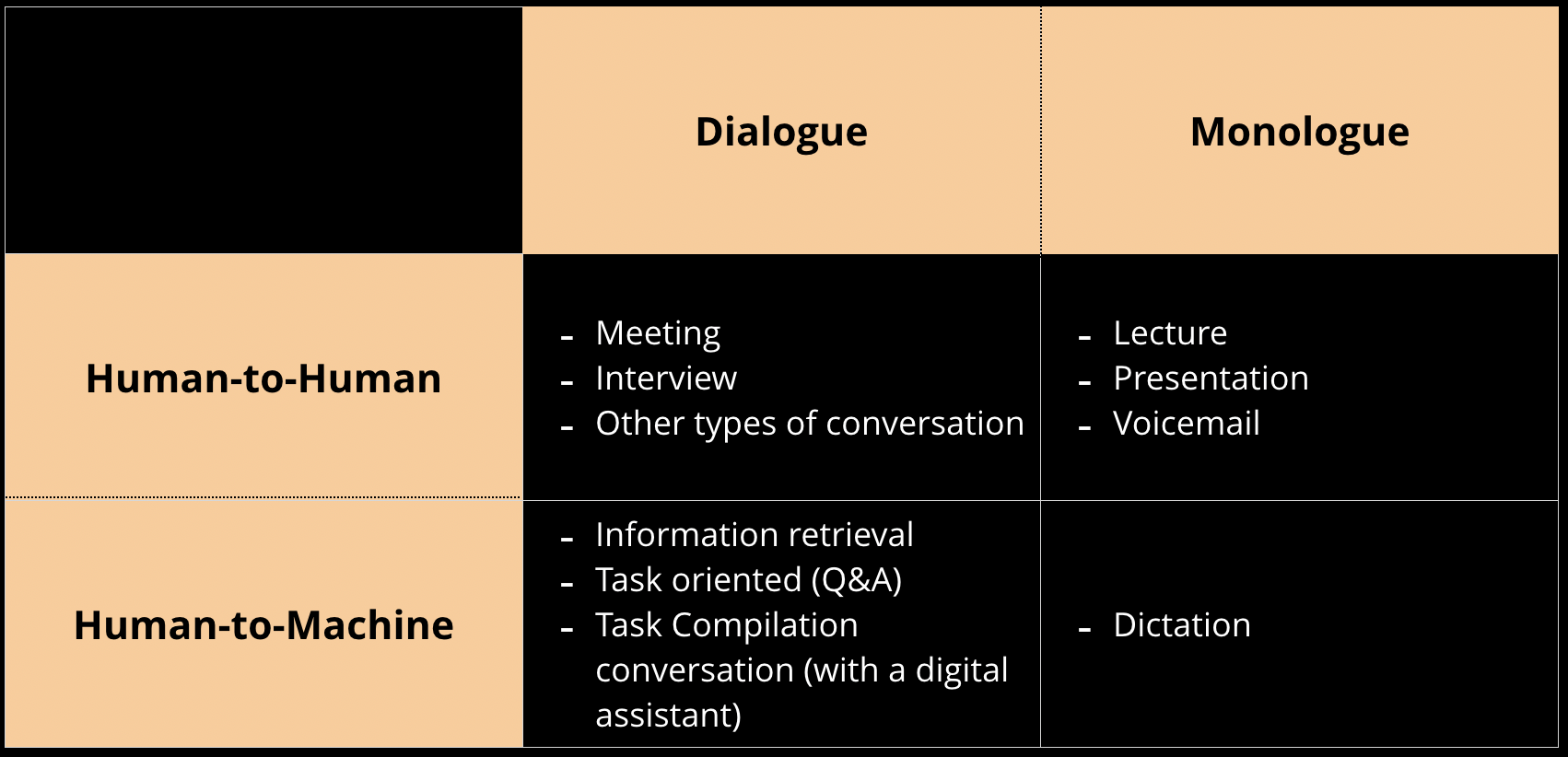
Voice and conversational applications can be challenging
Unlike text and NLP, or computer vision, where one can pull together simple applications, voice applications—that venture beyond simple voice commands—remain challenging for many organizations. Spoken language tends to be “noisier” than written text. For example, having read many podcast transcripts, we can attest that transcripts from spoken conversations still require a lot of editing. Even if you have access to the best transcription (speech-to-text) technology available, you often end up with a document with sentences that contain pauses, fillers, restarts, interjections (in the case of conversations), and ungrammatical constructs. The transcript may also contain passages that need to be refined due to the possibility that someone is “thinking out loud” or had trouble articulating or formulating specific points. Also, the resulting transcript may not be properly punctuated or capitalized in the right places. Thus, in many applications, post-processing of transcripts will require human editors.
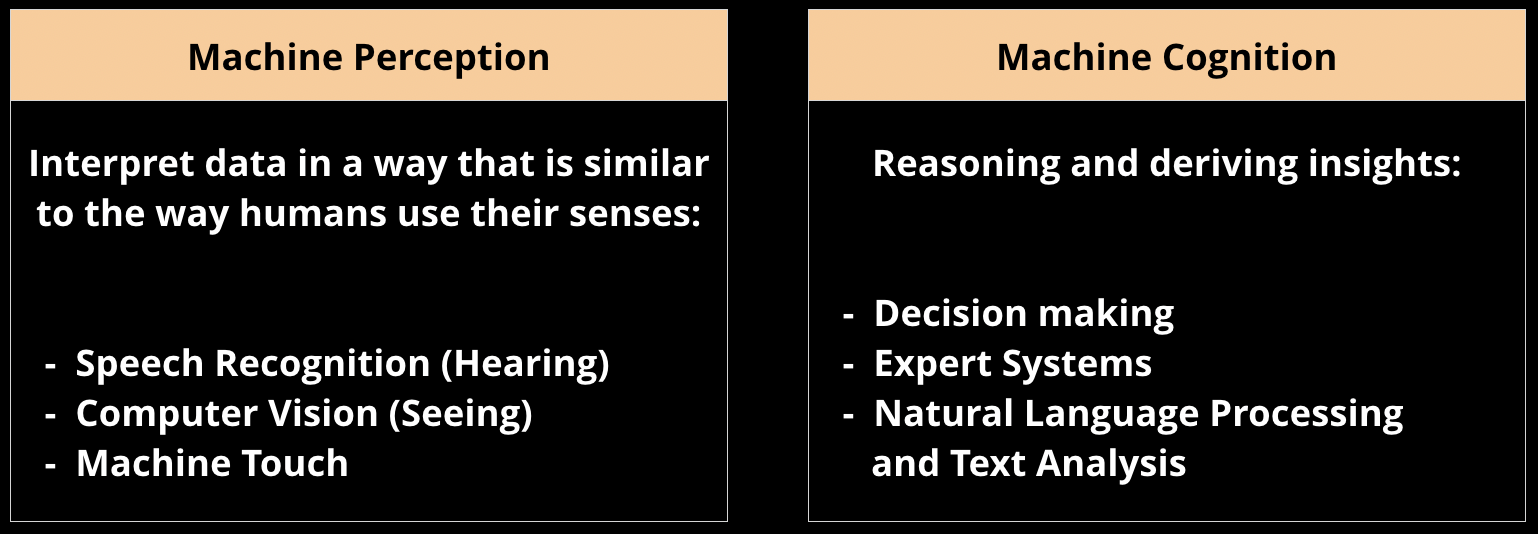
In computer vision (and now in NLP), we are at a stage where data has become at least as important as algorithms. Specifically, pre-trained models have achieved the state-of-the art in several tasks in computer vision and NLP. What about for speech? There are a few reasons why a “one size fits all” speech model hasn’t materialized:
- There are a variety of acoustic environments and background noises: indoor or outdoor, in a car, in a warehouse, or in a home, etc.
- Multiple languages (English, Spanish, Mandarin, etc.) may need to be supported, particularly in situations where speakers use (or mix and match) several languages in the course of conversations.
- The type of application (search, personal assistant, etc.) impacts dialog flow and vocabulary.
- Depending on the level of sophistication of an application, language models and vocabulary will need to be tuned for specific domains and topics. This is also true for text and natural language applications.
Building voice applications
Challenges notwithstanding, as we noted: there is already considerable excitement surrounding speech technologies and voice applications. We haven’t reached the stage where a general-purpose solution can be used to power a wide variety of voice applications, nor do we have voice-enabled intelligent assistants that can handle multiple domains.
There are, however, good building blocks from which one can assemble interesting voice applications. To assist companies that are exploring speech technologies, we assembled the following guidelines:
- Narrow your focus. As we noted, “one size fits all” is not possible with the current generation of speech technologies, so it is best to focus on specific tasks, languages, and domains.
- Understand the goal of the application, then backtrack to the types of techniques that will be needed. If you know the KPIs for your application, this will let you target the language models needed to achieve those metrics for the specific application domain.
- Experiment with “real data and real scenarios.” If you plan to get started by using off-the-shelf models and services, note that it is important to experiment with “real data and real scenarios.” In many cases, your initial test data will not be representative of how users will interact with the system you hope to deploy.
- Acquire labeled examples for each specific task. For example, recognizing the word “cat” in English and “cat” in Mandarin will require different models and different labeled data.
- Develop a data-acquisition strategy to gather appropriate data. Make sure you build a system that can learn as it gathers more data, and an iterative process that fosters ongoing improvement.
- Users of speech applications are concerned about outcomes. Speech models are only as interesting as the insights that can be derived and the actions that are taken using those insights. For example, if a user asks a smart speaker to play a specific song, the only thing that matters to this user is that it plays that exact song.
- Automate workflows. Ideally, the needed lexicon and speech models can be updated without much intervention (from machine learning or speech technology experts).
- Voice applications are complex end-to-end systems, so optimize when possible. Speech recognition systems alone are comprised of several building blocks which we described in a previous post. Training and retraining models can be expensive. Depending on the application and setup, latency and continuous connectivity can be important considerations.
From NLU to SLU
We are still in the early stages for voice applications in the enterprise. The past 12 months have seen rapid progress in pre-trained natural language models that set records across multiple NLP benchmarks. Developers are beginning to take these language models and tune them for specific domains and applications.
Speech adds another level of complexity—beyond natural language understanding (NLU)—to AI applications. Spoken language understanding (SLU) requires the ability to extract meaning from speech utterances. While SLU is not yet on hand for voice or speech applications, the good news is that one can already build simple, narrowly focused voice applications using existing models. To find the right use cases, companies will need to understand the limitations of current technologies and algorithms.
In the meantime, we’ll proceed in stages. As Alan Nichol noted in a post focused on text-based applications, “Chatbots are just the first step in the journey to achieve true AI assistants and autonomous organizations.” In the same way, today’s voice applications provide a very early glimpse of what is to come.
Related content:
- “Text analytics 101: Deep learning and attention networks all the way to production”: a new tutorial session at the Artificial Intelligence Conference in London
- “Deep learning revolutionizes conversational AI”
- “The next generation of AI assistants in enterprise”
- Yishay Carmiel: “Commercial speech recognition systems in the age of big data and deep learning”
- “Lessons learned building natural language processing systems in health care”
- Alan Nichol: “Using machine learning to improve dialog flow in conversational applications”
- “One simple chart: Who is interested in Spark NLP?”
- Ihab Ilyas and Ben Lorica: “The quest for high-quality data”