The Domain Name System is a distributed database. This structure allows local control of the segments of the overall database, yet data in each segment is available across the entire network through a client/server scheme. Robustness and adequate performance are achieved through replication and caching.
Programs called name servers constitute the server half of DNS’s client/server mechanism. Name servers contain information about some segments of the database and make that information available to clients, called resolvers. Resolvers are often just library routines that create queries and send them across a network to a name server.
The
structure of the DNS database, shown in Figure 1-1,
is similar to the structure of the Windows filesystem. The whole
database (or filesystem) is pictured as an inverted tree, with the
root node at the top. Each node in the tree has a text label, which
identifies the node relative to its parent. This is roughly analogous
to a “relative pathname” in a filesystem, like
bin. One label—the null label, or
“”—is reserved for the root node. In text, the root
node is written as a single dot (.). In the Windows filesystem, the
root is written as a backslash (\ ).
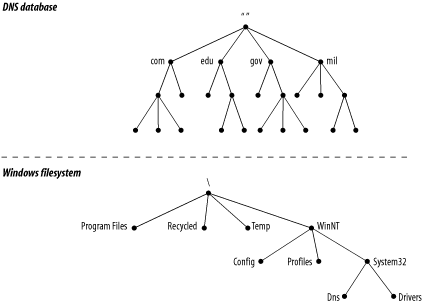
Each node is also the root of a new subtree of the overall tree. Each of these subtrees represents a partition of the overall database—a “directory” in the Windows filesystem, or a domain in the Domain Name System. Each domain or directory can be further divided into additional partitions, called subdomains in DNS, like a filesystem’s “subdirectories.” Subdomains, like subdirectories, are drawn as children of their parent domains.
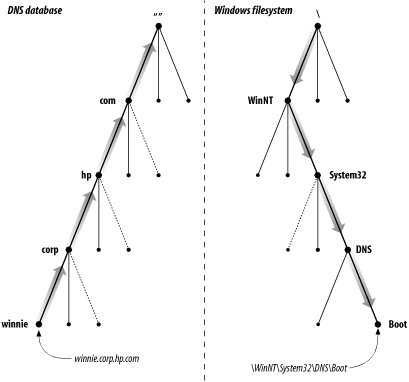
Every domain has a unique name, like every directory. A domain’s domain name identifies its position in the database, much as a directory’s “absolute pathname” specifies its place in the filesystem. In DNS, the domain name is the sequence of labels from the node at the root of the domain to the root of the whole tree, with dots (.) separating the labels. In the Windows filesystem, a directory’s absolute pathname is the list of relative names read from root to leaf (the opposite direction from DNS, as shown in Figure 1-2), using a slash to separate the names.
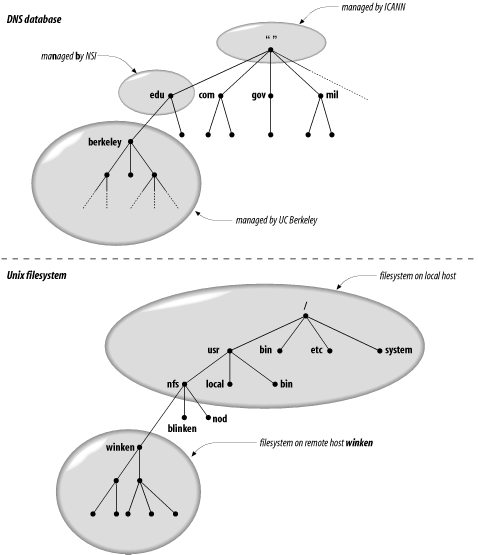
In DNS, each domain can be broken into a number of subdomains, and
responsibility for those subdomains can be doled out to different
organizations. For example, the InterNIC runs the
edu (educational) domain, but delegates
responsibility for the berkeley.edu subdomain to
U.C. Berkeley (Figure 1-3). This is similar to
remotely mounting a filesystem: certain directories in a filesystem
may actually be filesystems on other hosts, mounted from remote
hosts. The administrator on host winken, for
example (again, Figure 1-3), is responsible for the
filesystem that appears on the local host as the directory
/usr/nfs/winken.
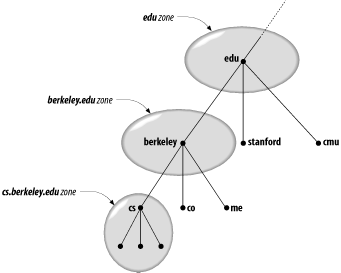
Delegating authority for berkeley.edu to U.C. Berkeley creates a new zone, an autonomously administered piece of the namespace. The zone berkeley.edu is now independent from edu, and contains all domain names that end in berkeley.edu. The zone edu, on the other hand, contains only domain names that end in edu but aren’t in delegated zones like berkeley.edu. berkeley.edu may be further divided into subdomains, like cs.berkeley.edu, and some of these subdomains may themselves be separate zones, if the berkeley.edu administrators delegate responsibility for them to other organizations. If cs.berkeley.edu is a separate zone, the berkeley.edu zone doesn’t contain domain names that end in cs.berkeley.edu (Figure 1-4).
Domain names are used as indexes into the DNS database. You might think of data in DNS as “attached” to a domain name. In a filesystem, directories contain files and subdirectories. Likewise, domains can contain both hosts and subdomains. A domain contains those hosts and subdomains whose domain names are within the domain.
Each host on a network has a domain name, which points to information about the host (see Figure 1-5). This information may include IP addresses, information about mail routing, etc. Hosts may also have one or more domain name aliases, which are simply pointers from one domain name (the alias) to another (the official or canonical domain name). In Figure 1-5, mailhub.nv... is an alias for the canonical name rincon.ba.ca....
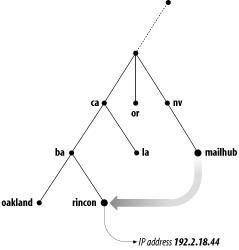
Why all the complicated structure? To solve the problems that
HOSTS.TXT had. For example, making domain names
hierarchical eliminates the pitfall of name collisions. Each domain
has a unique domain name, so the organization that runs the domain is
free to name hosts and subdomains within its domain. Whatever name
they choose for a host or subdomain won’t conflict with other
organizations’ domain names, since it will end in their unique
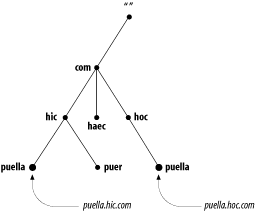
domain name. For example, the organization that runs
hic.com can name a host
puella (as shown in Figure 1-6), since it knows that the host’s domain
name will end in hic.com, a unique domain
name.
Get DNS on Windows 2000, Second Edition now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

