July 2020
Intermediate to advanced
397 pages
9h 49m
English
In earlier chapters, you learned how to use structured APIs to process very large but finite volumes of data. However, often data arrives continuously and needs to be processed in a real-time manner. In this chapter, we will discuss how the same Structured APIs can be used for processing data streams as well.
Stream processing is defined as the continuous processing of endless streams of data. With the advent of big data, stream processing systems transitioned from single-node processing engines to multiple-node, distributed processing engines. Traditionally, distributed stream processing has been implemented with a record-at-a-time processing model, as illustrated in Figure 8-1.
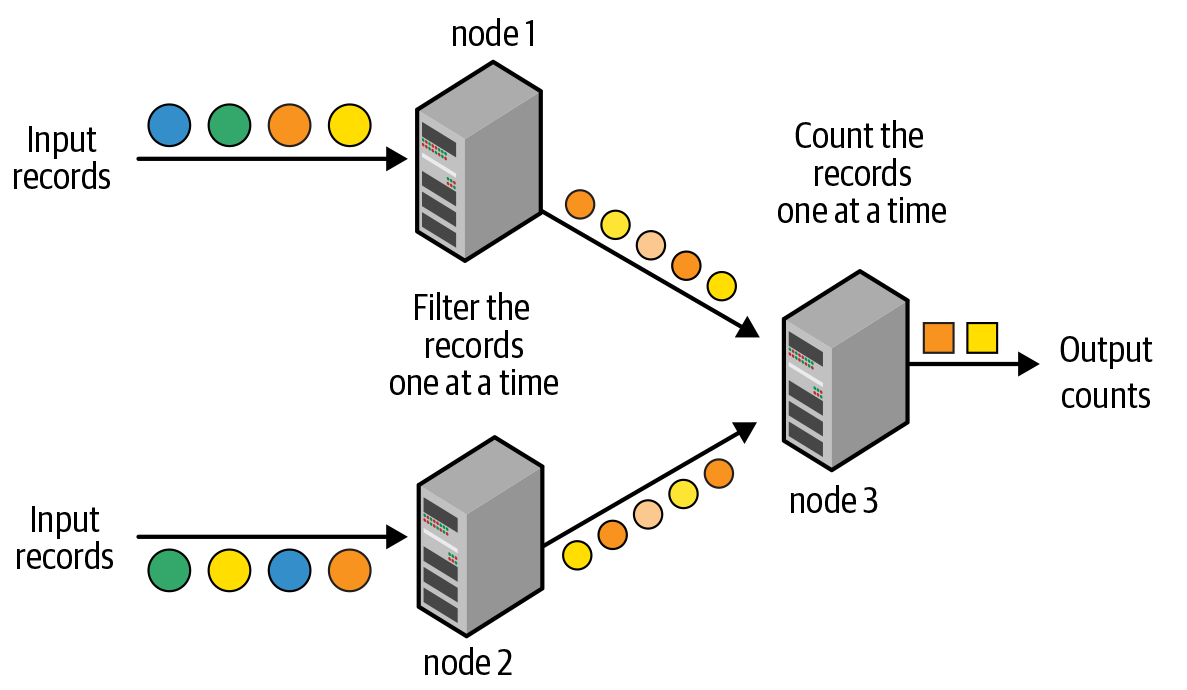
The processing pipeline is composed of a directed graph of nodes, as shown in Figure 8-1; each node continuously receives one record at a time, processes it, and then forwards the generated record(s) to the next node in the graph. This processing model can achieve very low latencies—that is, an input record can be processed by the pipeline and the resulting output can be generated within milliseconds. However, this model is not very efficient at recovering from node failures and straggler nodes (i.e., nodes that are slower than others); it can either recover ...
Read now
Unlock full access






