March 2025
Intermediate to advanced
418 pages
12h 29m
French
Une application populaire des LLM, , consiste à les utiliser pour générer du contenu basé à la fois sur des prompts d'entrée et des informations extraites de l'extérieur. Dans cette annexe, nous allons montrer comment construire un pipeline qui exploite un LLM pré-entraîné et un transformateur de phrases pré-entraîné pour générer du contenu en fonction des entrées de l'utilisateur et d'un ensemble de documents. Nous avons exploré les éléments de base de cette méthode tout au long du livre. Le chapitre 2 a abordé la génération de texte avec les LLMs et la manière d'utiliser les transformateurs de phrases pour encoder le texte. Le chapitre 6 contenait également un projet dans lequel nous avons construit un pipeline RAG minimal.
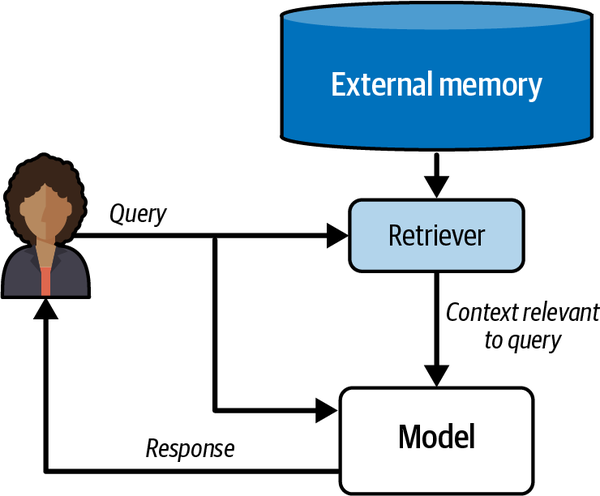
Discutons des composants d'un système RAG (illustré schématiquement à la figure C-1) :
L'utilisateur saisit une question.
Le pipeline récupère les documents les plus similaires à la question.
Le pipeline transmet à la fois la question et les documents récupérés au LLM.
Le pipeline génère une réponse.
Comme pour tout projet de ML, la première étape consiste à charger et à traiter les données. Nous allons faire simple en nous concentrant sur un seul sujet. Imaginons que nous voulions que notre modèle génère du contenu lié à la ...
Read now
Unlock full access






