March 2025
Intermediate to advanced
428 pages
11h 23m
Italian
Questo lavoro è stato tradotto utilizzando l'AI. Siamo lieti di ricevere il tuo feedback e i tuoi commenti: translation-feedback@oreilly.com
Un compito comune nell'elaborazione del linguaggio naturale è la classificazione. L'obiettivo del compito è addestrare un modello per assegnare un'etichetta o una classe a un testo in ingresso (vedi Figura 4-1). La classificazione del testo viene utilizzata in tutto il mondo per un'ampia gamma di applicazioni, dall'analisi del sentimento al rilevamento delle intenzioni, dall'estrazione di entità al rilevamento del linguaggio. L'impatto dei modelli linguistici, sia rappresentativi che generativi, sulla classificazione non può essere sottovalutato.
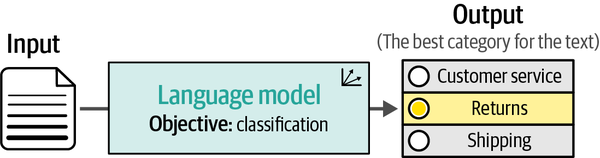
In questo capitolo discuteremo diversi modi per utilizzare i modelli linguistici per classificare il testo. Si tratta di un'introduzione accessibile all'uso di modelli linguistici già addestrati. Data l'ampiezza del campo della classificazione del testo, discuteremo diverse tecniche e le utilizzeremo per esplorare il campo dei modelli linguistici:
"Classificazione del testo con modelli di rappresentazione" dimostra la flessibilità dei modelli non generativi per la classificazione. Tratteremo sia i modelli specifici per le attività che i modelli di incorporazione.
Read now
Unlock full access






