March 2025
Intermediate to advanced
428 pages
11h 23m
Italian
Questo lavoro è stato tradotto utilizzando l'AI. Siamo lieti di ricevere il tuo feedback e i tuoi commenti: translation-feedback@oreilly.com
Sebbene le tecniche supervisionate di, come la classificazione, abbiano regnato sovrane negli ultimi anni nel settore, il potenziale delle tecniche non supervisionate, come il clustering del testo, non può essere sottovalutato.
Il raggruppamento di testi mira a raggruppare testi simili in base al loro contenuto semantico, al loro significato e alle loro relazioni. Come illustrato nella Figura 5-1, i cluster di documenti semanticamente simili che ne derivano non solo facilitano la categorizzazione efficiente di grandi volumi di testo non strutturato, ma consentono anche una rapida analisi esplorativa dei dati.
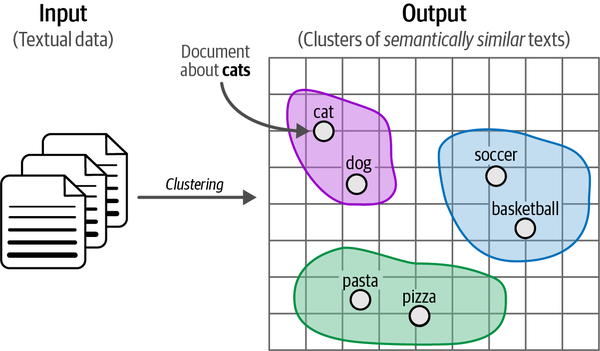
La recente evoluzione dei modelli linguistici, che consentono rappresentazioni contestuali e semantiche del testo, ha migliorato l'efficacia del clustering testuale. Il linguaggio è molto più di un insieme di parole e i recenti modelli linguistici hanno dimostrato di essere in grado di catturare questa nozione. Il clustering del testo, svincolato dalla supervisione, consente soluzioni creative e applicazioni diverse, come la ricerca di outlier, l'accelerazione dell'etichettatura e l'individuazione di dati etichettati ...
Read now
Unlock full access






