March 2025
Intermediate to advanced
428 pages
11h 23m
Italian
Questo lavoro è stato tradotto utilizzando l'AI. Siamo lieti di ricevere il tuo feedback e i tuoi commenti: translation-feedback@oreilly.com
Quando pensi ai grandi modelli linguistici (LLMs), la multimodalità potrebbe non essere la prima cosa che ti viene in mente. Dopo tutto, si tratta di modelli linguistici! Ma possiamo subito capire che i modelli possono essere molto più utili se sono in grado di gestire tipi di dati diversi dal testo. Ad esempio, è molto utile se un modello linguistico è in grado di dare un'occhiata a un'immagine e rispondere a domande su di essa. Un modello che è in grado di gestire testo e immagini (ognuna delle quali è chiamata modalità) è detto multimodale, come si può vedere nella Figura 9-1.
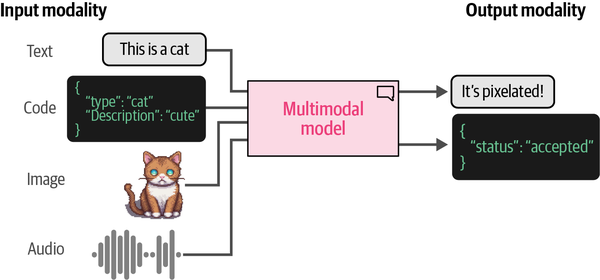
Abbiamo visto nascere dagli LLMs ogni sorta di comportamento emergente, dalle capacità di generalizzazione e ragionamento all'aritmetica e alla linguistica. Man mano che i modelli diventano più grandi e più intelligenti, crescono anche le loro abilità.1
La capacità di ricevere e ragionare con input multimodali potrebbe aumentare ulteriormente e ...
Read now
Unlock full access






