July 2025
Intermediate to advanced
444 pages
7h 8m
Japanese
この作品はAIを使って翻訳されている。ご意見、ご感想をお待ちしている:translation-feedback@oreilly.com
第2章では、ファッションMNISTデータセットの入力ピクセルを10個のラベルにマッチさせる単純なニューラルネットワークを作成することで、コンピュータ・ビジョンを始める方法 を学んだ。そして、服の種類を検出するのに非常に優れたネットワークを作成したが、明らかな欠点があった。あなたのニューラルネットワークは小さなモノクロ画像でトレーニングされ、それぞれの画像には服が1点しかコンテナに入っておらず、各アイテムは画像内の中央に配置されていた。
モデルを次のレベルに引き上げるには、画像の特徴を検出できるようにする必要がある。例えば、単に画像の生のピクセルを見るのではなく、画像を構成する要素までフィルタリングできたらどうだろう?生のピクセルの代わりにそれらの要素をマッチングさせれば、モデルはより効果的に画像の内容を検出できるようになる。例えば、前章で使用したファッションMNISTデータセットを考えてみよう。靴を検出するとき、ニューラルネットワークは画像の底に集まったたくさんの暗いピクセルによって活性化されたかもしれない。しかし、靴が中央になく、フレームを埋めていなければ、このロジックは成り立たない。
特徴を検出するメソッドのひとつは、写真や画像処理の方法論に由来する。PhotoshopやGIMPのようなツールを使って画像をシャープにしたことがあるなら、画像のピクセルに作用する数学的フィルタを使ったことがあるだろう。このようなフィルターが行うことを別の言葉で表すとコンボリューション(畳み込み)で、このようなフィルターをニューラルネットワークで使用することで、畳み込みニューラルネットワーク(CNN)を作成することになる。
この章では、まず畳み込みを使って画像の特徴を検出する方法について学ぶ。次に、画像内の特徴に基づいて画像を分類する方法について深く掘り下げる。さらに、より多くの特徴を得るための画像の補強や、他の人が学習した既存の特徴を取り込むための転移学習についても調べ、ドロップアウトを使ってモデルを最適化する方法についても簡単に説明する。
畳み込みとは、単純に 、ピクセルの新しい値を得るために、ピクセルとその近傍のピクセルを掛け合わせるために使われる重みのフィルタリングである。例えば、ファッションMNISTのアンクルブーツ画像とそのピクセル値を考えてみよう(図3-1参照)。
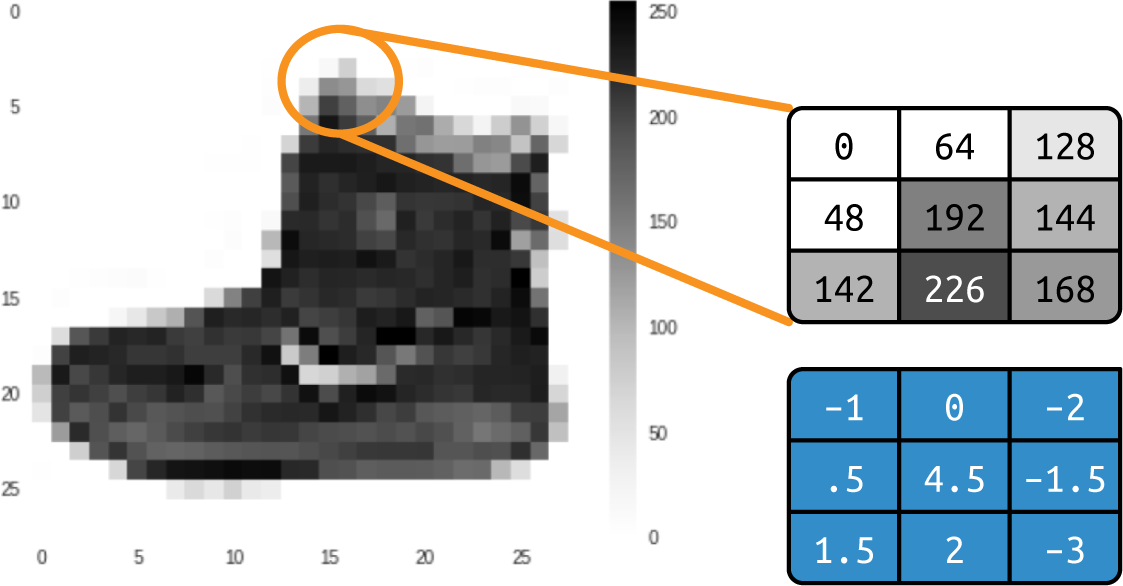
選択範囲の真ん中のピクセルを見ると、192という値を持っていることがわかる。(Fashion MNISTはピクセル値が0から255までのモノクロ画像を使用していることを思い出してほしい)。上と左のピクセルは値0、すぐ上のピクセルは値64などである。
同じ3×3グリッドでフィルタを定義すると、元の値の下に示すように、そのピクセルの新しい値を計算して変換することができる。これは、グリッド内の各ピクセルの現在の値に、フィルタリング・グリッド内の同じ位置の値を掛け合わせ、合計することで行う。この合計が現在のピクセルの新しい値となり、画像内のすべてのピクセルについてこの計算を繰り返す。 ...
Read now
Unlock full access






