July 2025
Intermediate to advanced
444 pages
7h 8m
Japanese
この作品はAIを使って翻訳されている。ご意見、ご感想をお待ちしている:translation-feedback@oreilly.com
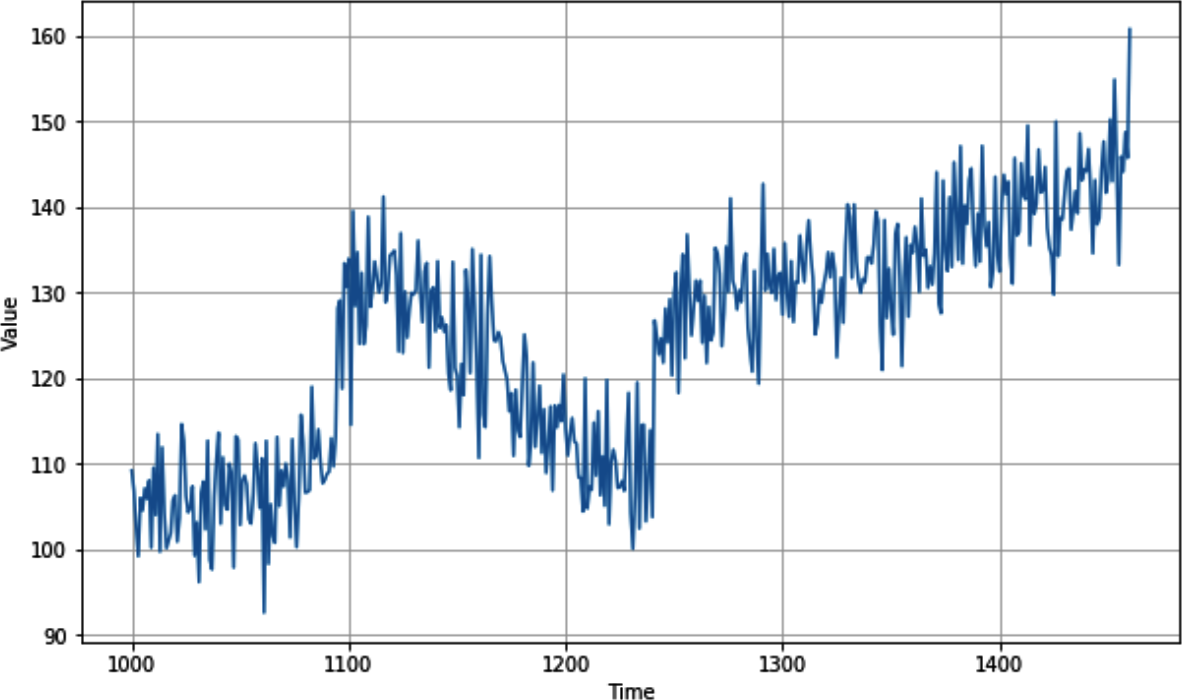
第9章では、シーケンスデータと、季節性、トレンド、自己相関、ノイズを含む時系列の属性を紹介した。予測に使用する合成系列を作成し、基本的な統計的予測の方法を探った。
次の数章では、予測のためのMLの使い方を学ぶ。しかし、モデルの作成を始める前に、予測モデルをトレーニングするための時系列データをどのように構成するかを理解する必要がある 。
なぜそうする必要があるのかを理解するために、第9章で作成した時系列を考えてみよう。図10-1にそのプロットがある。
例えば、タイム・ステップ1,200における時系列の値を、それに先立つ30個の値の関数として予測したいとする。この場合、時間ステップ1,170~1,199の値が時間ステップ1,200の値を決定することになる(図10-2参照)。
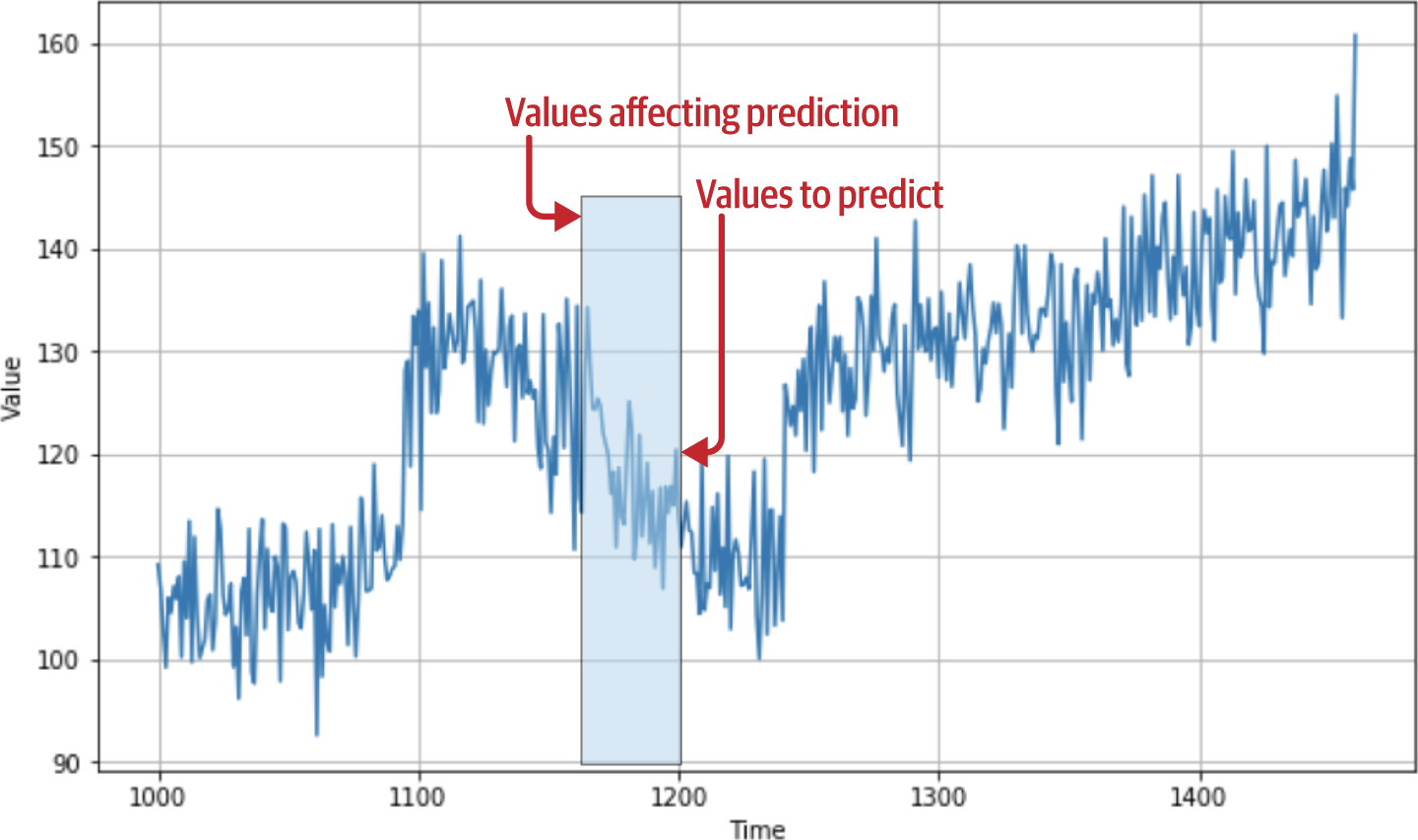
1,170から1,199の値を特徴量、1,200の値をラベルと考えればよい。データセットを、ある数の値を特徴として、それに続く値をラベルとする条件付きにし、データセット内の既知の値すべてについてこれを行えば、モデルの学習に使える、かなりまともな特徴とラベルのセットができあがる。
第9章の時系列データセットでこれを行う前に、同じ属性を持つがデータ量ははるかに少ない、非常に単純なデータセットを作成してみよう。
PyTorchにはデータを操作するのに便利なAPIがたくさんある。例えば、torch.arange(10) を使って0-9の数字を含む基本的なデータセットを作成し、時系列をエミュレートすることができる。そして、そのデータセットをウィンドウ・データセットの始まりに変えることができる。これがそのコードである:
importtorchdefcreate_sliding_windows(data,window_size,shift=1):# Convert input to tensor if it isn't alreadyifnotisinstance(data,torch.Tensor):data=torch.tensor(data)# Calculate number of valid windowsn=len(data)num_windows=max(0,(n–window_size)//shift+1)# Create strided view of datawindows=data.unfold(0,window_size,shift)returnwindows# Example usage:data=torch.arange(10)windows=create_sliding_windows ...
Read now
Unlock full access






