July 2025
Intermediate to advanced
444 pages
7h 8m
Japanese
この作品はAIを使って翻訳されている。ご意見、ご感想をお待ちしている:translation-feedback@oreilly.com
ここ数章にわたり、我々は 、生成モデルの推論について見てきた。主にLLM(別名テキスト間モデル)を使って様々なシナリオを探ってきた。しかし、生成AIはテキストベースのモデルだけに限定されるものではなく、もう一つの重要な革新は、もちろん画像生成(別名テキストから画像へ)である。今日、ほとんどの画像生成モデルは拡散と呼ばれるプロセスに基づいている。これは、テキストプロンプトから画像を作成するために使用されるHugging Face APIのディフューザーという名前の由来となっている。この章では、ディフュージョンモデルがどのように機能するのか、また、プロンプトから画像を生成できる独自のアプリを立ち上げて実行する方法を探る。
AIが作成した 画像を見たことがある人は多いだろう。抽象化されたラフな表現から、プロンプトで要求されたものをフォトリアルに近い表現に成長させる速さに驚いたことがあるだろう。このモデルは、より長いプロンプトをより詳細に表現することができ、トレーニングセットが成長するにつれて、AI画像生成でできることがほぼ無限に改善されている。
しかし、これらはどのように機能するのだろうか?それは拡散のアイデアから始まる。
このプロセスは、画像とそれに関連するノイズのデータセットを作成することから始めることができる。図19-1を考えてみよう。

そして、このようにノイズの多い画像のセットができたら、画像を元の状態に戻すためにどのようにノイズ除去するかを学習するモデルを訓練することができる。ノイズをデータ、元の画像をラベルと考える。つまり、図19-1の場合、右側のノイズがデータ、子犬の画像がラベルとなる。この点で、ノイズを見たときに、そのノイズを画像に変換する方法を見つけ出すモデルを訓練することができる。論理的な拡張としては、ノイズを発生させれば、モデルはそのノイズをトレーニングセットにある画像に少し似た画像に変える方法を見つけ出すということだ。
しかし、ノイズ画像を作成するステップ( )に戻り、そこに非常に冗長な説明のテキストを追加したらどうなるだろうか?すると、ノイズ画像にテキスト・ラベル(埋め込みで表現)が付加される(図19-2参照)!
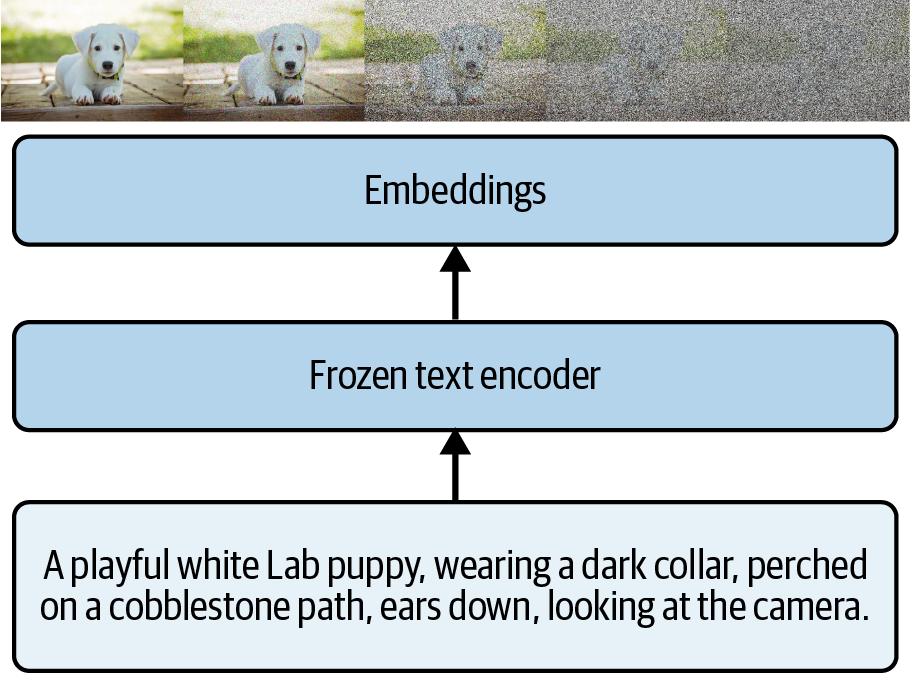
さて、ノイズ画像にはそれを説明する埋め込みが付加されている。簡単に言えば、ノイズの一部はそれを記述する埋め込みによって強調されるので、この画像を元の子犬の画像に戻すノイズ除去処理には、どのようにノイズ除去を行うかの指針となるデータが追加される。つまり、ノイズ+埋め込みをデータ、元の画像をラベルとしてモデルを訓練すれば、ノイズ+埋め込みを画像に変換する方法を、より効果的に学習できるようになる。
Read now
Unlock full access






