March 2025
Intermediate to advanced
606 pages
9h
Japanese
この作品はAIを使って翻訳されている。ご意見、ご感想をお待ちしている:translation-feedback@oreilly.com
このように この本では、プログラミングインタフェースとしてのSparkの特性に焦点を当てた。構造化APIがどのように論理演算を行い、それを論理プランに分割し、クラスタマシン全体で実行されるRDD(Resilient Distributed Dataset)演算で構成される物理プランに変換するかを説明した。この章では、Sparkがそのコードを実行するときに何が起こるかに焦点を当てる。実装にとらわれない方法でこれを議論する。これは、使用しているクラスタマネージャにも、実行しているコードにも依存しない。結局のところ、Sparkのコードはすべて同じように実行される。
この章では、いくつかの重要なトピックを取り上げる:
Sparkアプリケーションのアーキテクチャとコンポーネント
SparkアプリケーションのライフサイクルをSparkの内部と外部で考える
パイプラインなどの重要な低レベル実行プロパティ
Sparkアプリケーションを実行するために必要なこと、第16章への分岐点として。
まずはアーキテクチャから見ていこう。
第2章では、Sparkアプリケーションのハイレベルなコンポーネントについて説明した。もう一度おさらいしよう:
ドライバは、Sparkアプリケーションの "運転席に座る "プロセスである。Sparkアプリケーションの実行を制御し、Sparkクラスタのすべての状態(エクゼキュータの状態とタスク)を維持する。実際に物理リソースを取得し、エクゼキュータを起動するためには、クラスタ・マネージャーとインタフェースする必要がある。結局のところ、これは物理マシン上のプロセスに過ぎず、クラスタ上で実行されているアプリケーションの状態を維持する役割を担っている。
Spark エグゼキューターは、Sparkドライバーによって代入されたタスクを実行するプロセスである。ドライバーから代入されたタスクを実行し、その状態(成功か失敗か)と結果を報告する。各Sparkアプリケーションは、それぞれ独立したエクゼキュータ・プロセスを持っている。
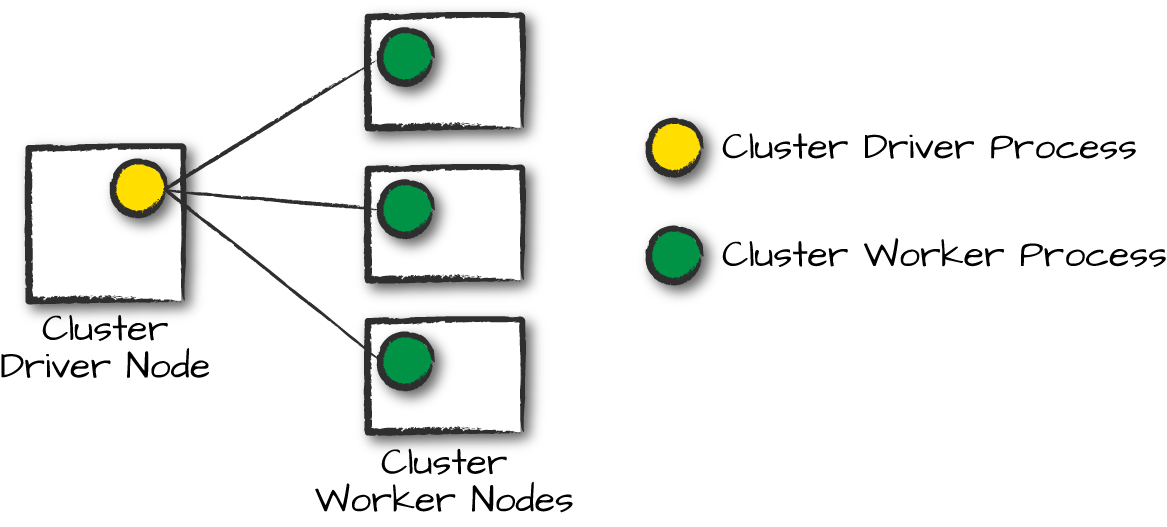
Spark DriverとExecutorは空中に存在するわけではないので、クラスタ・マネージャの出番となる。クラスタマネージャは、Sparkアプリケーションを実行するマシンのクラスタを管理する。少し紛らわしいが、クラスターマネージャーは独自の "ドライバー"(マスターと呼ばれることもある)と "ワーカー "の抽象化を持つ。主な違いは、これらが(Sparkのように)プロセスではなく物理マシンに結びついていることだ。図15-1は基本的なクラスタのセットアップを示している。図の左側のマシンはクラスタマネージャードライバノードである。円は個々のワーカーノード上で動作し、管理しているデーモンプロセスを表す。まだSparkアプリケーションは実行されていない-これらはクラスタマネージャからのプロセスだけである。
Read now
Unlock full access






