March 2025
Intermediate to advanced
606 pages
9h
Japanese
この作品はAIを使って翻訳されている。ご意見、ご感想をお待ちしている:translation-feedback@oreilly.com
第21章では、 、コア概念と基本APIについて説明した。本章では、イベント・タイム処理とステートフル処理について掘り下げていく。イベント・タイム(Event-time) 処理は、処理された時間ではなく、作成された時間を基準に情報を分析するため、ホットなトピックである。この処理スタイルのキーとなる考え方は、ジョブのライフタイムを通じて、Sparkが関連する状態を保持し、ジョブの過程で更新してからシンクに出力するというものだ。
これらの概念が機能することをコードで示す前に、これらの概念について詳しく説明しよう。
SparkのDStream APIは、イベント時間に関する処理情報をサポートしていないためである。より高いレベルでは、ストリーム処理システムでは、各イベントに関連する時間が実質的に2つ存在する:それが実際に発生した時間(イベント時間)と、それが処理された、またはストリーム処理システムに到達した時間(処理時間)。
イベント 時間とは、データそのものに埋め込まれている時間のことである。多くの場合、必ずしもそうである必要はないが、イベントが実際に発生した時刻である。これは、イベント同士を比較するのにより堅牢な方法を提供するため、使用することが重要である。ここでの課題は、イベントデータが遅れたり、順序が狂っていたりすることである。つまり、ストリーム処理システムは、順序が狂っていたり、遅れたりするデータを処理できなければならない。
処理時間 ストリーム処理システムが実際にデータを受信する時間である。いつ処理されるかは実装の詳細であるため、通常はイベント時間よりも重要度は低い。これは、ある時刻におけるストリーミング・システムの特性であるため(イベント時刻のような外部システムではない)、順番が狂うことはない。
の説明は抽象化されているので、もっと具体的な例で説明しよう。サンフランシスコにデータセンターがあるとする。あるイベントが、エクアドルとバージニアの2箇所で同時に発生した(図22-1参照)。
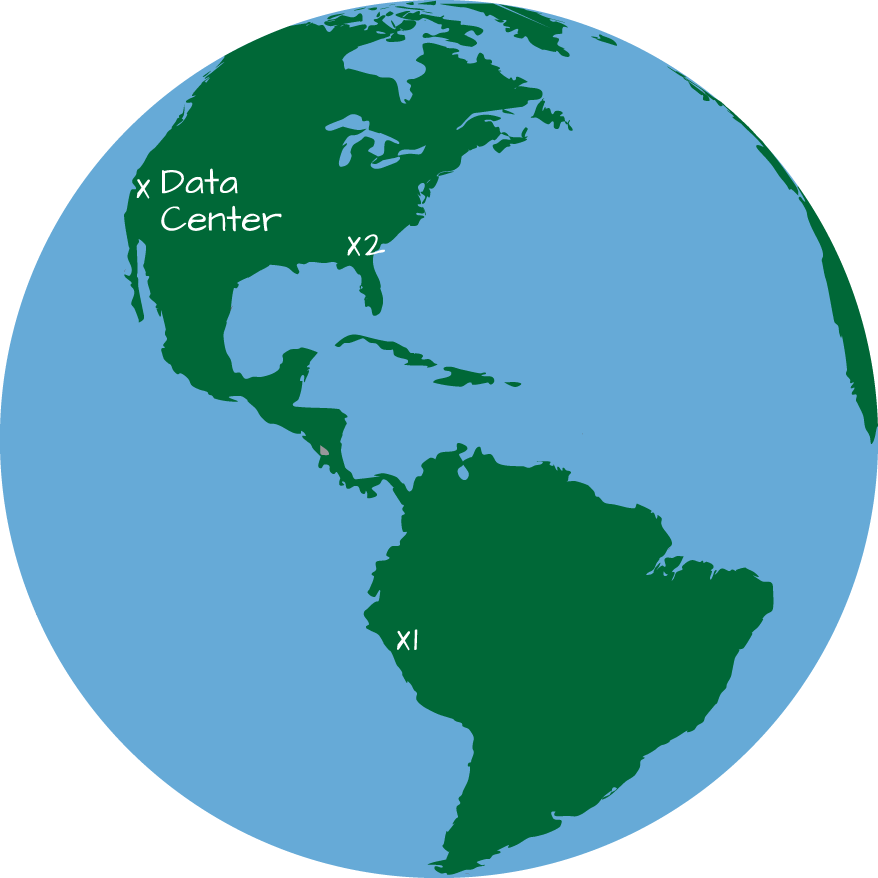
データセンターの位置により、エクアドルでのイベントより先にバージニアでのイベントがデータセンターに表示される可能性が高い。このデータを処理時間に基づいて分析すると、バージニアのイベントがエクアドルのイベントより先に発生したように見える。しかし、イベント時間に基づいてデータを分析すれば(処理された時間はほとんど無視される)、これらのイベントは同時に発生したことがわかるだろう。
前述したように、基本的な考え方は、処理システムにおける一連のイベントの順序は、イベント時間における順序を保証するものではないということである。これはやや直感に反するかもしれないが、強調しておく価値がある。コンピュータネットワークは信頼できない。つまり、イベントがドロップされたり、遅くなったり、繰り返されたり、問題なく送信されたりする可能性がある。個々のイベントの運命は保証されていないため、情報源からストリーム処理システムまでの過程で、これらのイベントに様々なことが起こりうることを認識しなければならない。このため、イベント時刻で演算子し、システムに到着した時刻ではなく、データに含まれるこの情報を参照してストリーム全体を見る必要がある。つまり、イベントが発生した時間に基づいて、イベントを比較したいのである。 ...
Read now
Unlock full access






