March 2025
Intermediate to advanced
606 pages
9h
Japanese
この作品はAIを使って翻訳されている。ご意見、ご感想をお待ちしている:translation-feedback@oreilly.com
前章では、従来の教師なしテクニックをいくつか取り上げた。この章では、より特殊化されたツールセットであるグラフ処理に飛び込む。グラフ は、任意のオブジェクトであるノード(頂点)と、これらのノード間の関係を定義するエッジから構成されるデータ構造である。グラフ分析とは、これらの関係を分析するプロセスである。グラフの例は、あなたの友人グループかもしれない。グラフ分析の文脈では、各頂点またはノードは人を表し、各辺は関係を表す。図30-1にグラフのサンプルを示す。
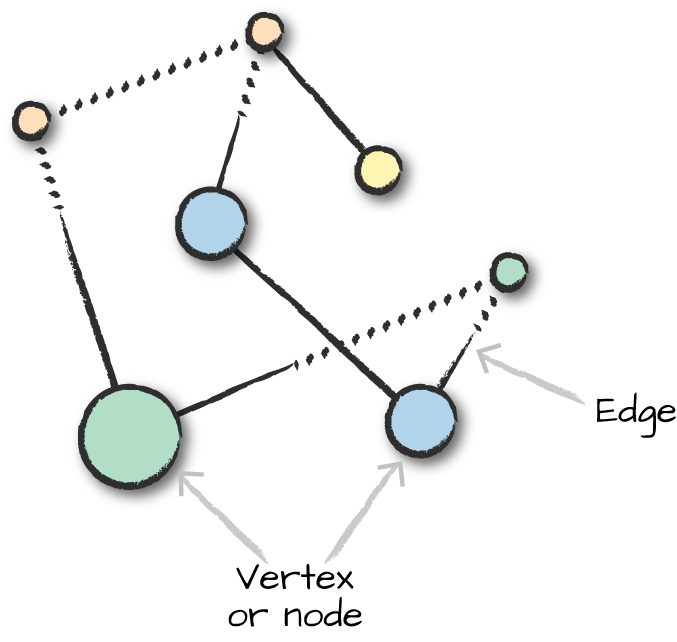
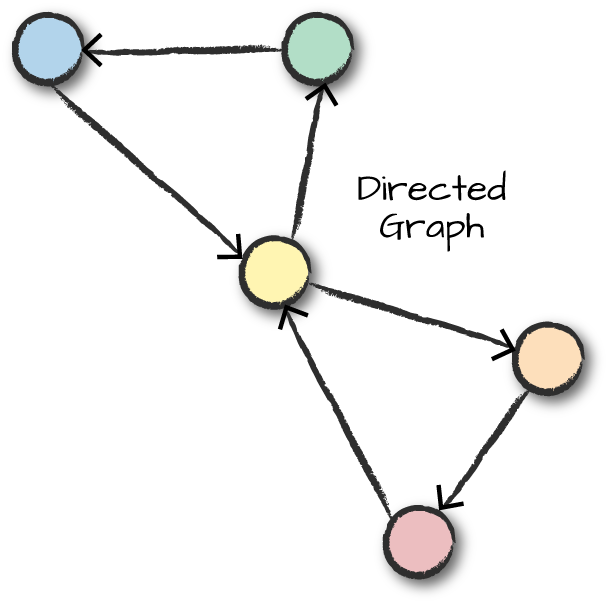
このグラフは無向グラフであり、辺には「始点」と「終点」が指定されていない。始点と終点を指定する有向グラフもある。図30-2は 、辺に方向性がある有向グラフである。
グラフの辺や頂点は、それらに関連するデータを持つこともできる。友人の例では、エッジの重みは異なる友人間の親密度を表すかもしれない。知人同士は重みの小さいエッジを持ち、既婚者は重みの大きいエッジを持つだろう。ノード間のコミュニケーション頻度を調べ、それに応じてエッジの重みを設定することで、この値を設定することができる。各頂点(人)は名前などのデータも持つかもしれない。
グラフは、関係や様々な問題セットを記述する自然な方法であり、Sparkはこの分析パラダイムで作業する方法をいくつか提供している。ビジネスでの使用例としては、クレジットカード詐欺の発見、モチーフ発見、書誌ネットワークにおける論文の重要性の判断(つまり、どの論文が最も参照されているか)、 GoogleがPageRankアルゴリズムを使って行ったことで有名なWebページのランキングなどが考えられる。
Spark には以前から、グラフ処理を実行するためのRDDベースのライブラリが含まれていた:GraphXだ。これは非常に強力な低レベルのインタフェースを提供するが、RDDと同様、使いやすくも最適化しやすくもなかった。GraphXは今でもSparkの中核部分である。企業はGraphXの上にプロダクション・アプリケーションを構築し続けており、GraphXは今でもマイナーな機能開発を行っている。GraphX APIはよくドキュメント化されている。しかし、Sparkの開発者の一部(GraphXのオリジナル作者の一部を含む)は最近、Spark上で次世代のグラフ 分析ライブラリを作成した:GraphFramesである。GraphFramesはGraphXを拡張してDataFrame APIを提供し、Pythonユーザがツールのスケーラビリティを活用できるように、Sparkの様々な言語バインディングをサポートしている。本書では、GraphFramesに焦点を当てる。
GraphFramesは現在Sparkパッケージとして提供されており、Sparkアプリケーションの起動時にロードする必要がある外部パッケージだが、将来的にはSparkのコアに統合されるかもしれない。GraphFramesのユーザ体験が大幅に向上することを除けば)ほとんどの場合、この2つの間にパフォーマンスの差はほとんどないはずだ。GraphFramesを使用する際に若干のオーバーヘッドが発生するが、ほとんどの場合、適切な場合はGraphXに呼び出そうとするため、ユーザ体験の向上はこの小さなオーバーヘッドを大きく上回る。 ...
Read now
Unlock full access






