May 2026
Intermediate
378 pages
5h 49m
Korean
이 작품은 AI를 사용하여 번역되었습니다. 여러분의 피드백과 의견을 환영합니다: translation-feedback@oreilly.com
LLMs(대규모 언어 모델)과 다중 모달 모델을 포함한 파운데이션 모델은 현대 RAG 시스템의 중추를 이룹니다. 이러한 모델은 사용자에게 답변을 생성하는 데 사용될 뿐만 아니라, 콘텐츠가 저장 및 검색되기 전에 이를 준비하는 데도 활용됩니다.
생성 단계에서 파운데이션 모델은 검색된 컨텍스트와 사용자의 질문을 분석하여 근거에 기반한 응답을 생성합니다. 준비 단계에서는 파운데이션 모델이 이미지에서 텍스트를 추출하고, 오디오를 텍스트로 변환하며, 긴 문서를 요약하고, 검색 품질을 향상시키는 메타데이터로 콘텐츠를 보강합니다.
이 장에서는 언어 모델( )과, 그리고 다중 모달 모델( )에 중점을 둡니다. 이러한 모델들은 콘텐츠가 처리, 변환 및 저장을 위해 준비되는 준비 단계 (인제스트 단계라고도 함)와, 모델이 검색된 정보를 분석하여 사용자를 위한 답변을 생성하는 생성 단계 모두에서 사용됩니다.
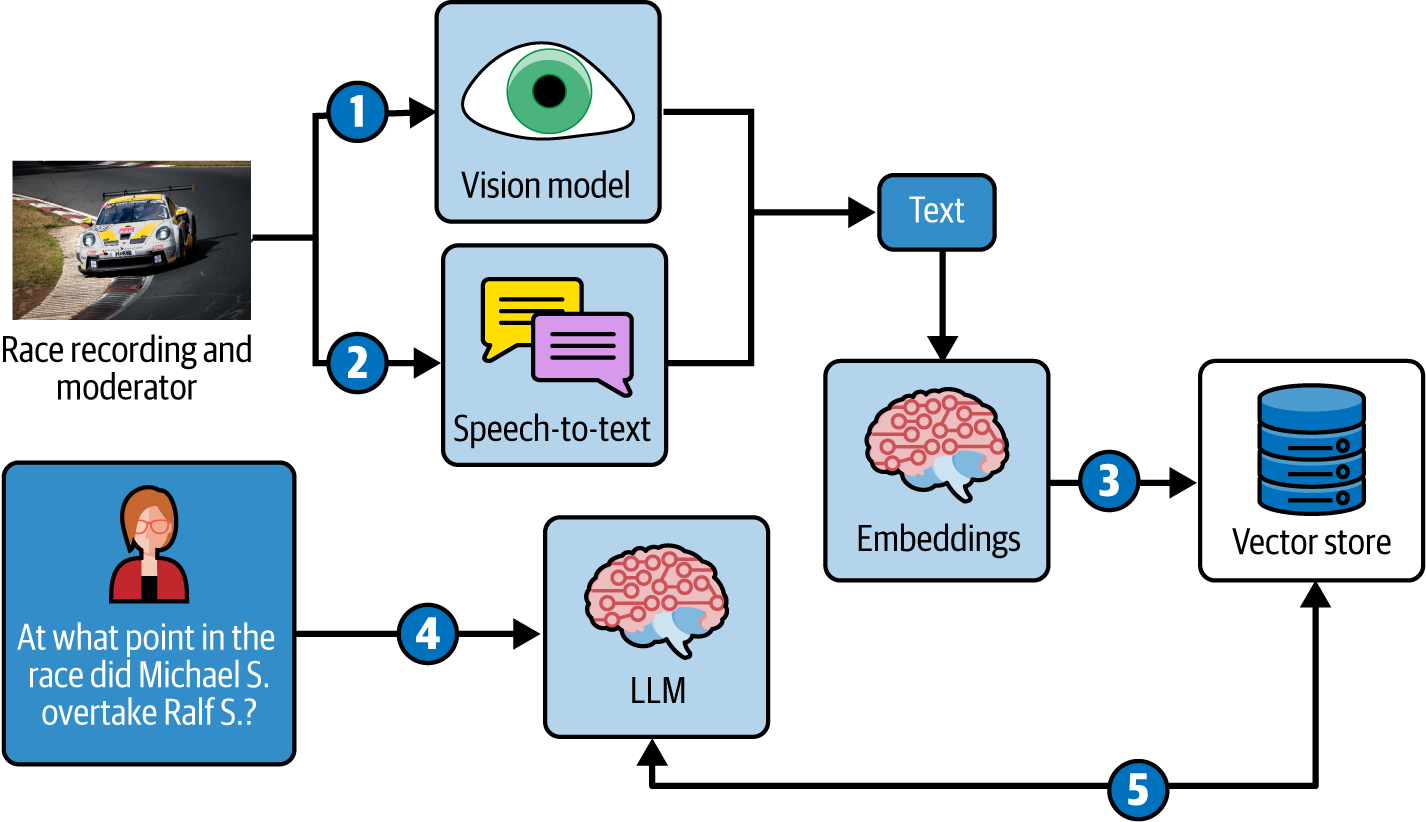
그림 2-1은 비디오 콘텐츠를 처리하기 위한 일반적인 다중 모드 워크플로우 를 보여줍니다:
비전 모델을 사용하여 비디오 프레임을 분석합니다.
음성 인식 기능을 사용하여 오디오를 텍스트로 변환합니다.
임베딩 모델을 사용하여 결과 텍스트를 임베딩합니다.
사용자가 질문할 때 관련 컨텍스트를 검색합니다.
언어 모델을 사용하여 답변을 생성합니다.
모든 RAG 시스템에는 검색된 콘텐츠를 해석하고 사용자 질문에 답변하거나, 보고서를 작성하거나, 기타 특정 작업을 수행하는 등 필요한 출력을 생성하는 생성 모델이 필요합니다. 다음 레시피에서는 효과적인 prompt를 설계하고, 적절한 모델을 선택하며, 구조화된 출력을 생성하는 방법을 보여줍니다.
이 장의 모든 코드 예제는 책의 GitHub 저장소에서 확인할 수 있습니다.
RAG 애플리케이션의 생성 단계를 위해 효과적인 prompt 템플릿을 정의해야 합니다.
RAG 애플리케이션의 경우 prompt는 구조화된 패턴을 따릅니다. 적절한 prompt 템플릿은 다음 네 가지 핵심 구성 요소로 이루어집니다:
어시스턴트의 행동 방식을 정의하는 역할
작업을 설명하는 지시문
모델이 반드시 참조해야 하는 검색된 컨텍스트
답변의 형식을 정의하는 출력 요구 사항
이 구조는 모델이 근거 있는 응답을 생성하도록 안내합니다. 검색된 컨텍스트만을 사용하도록 모델에 명시적으로 지시함으로써, 사용자는 나중에 출처를 검토하여 답변이 에서 생성된 허구적인 사실이 아닌 실제 정보에 기반했는지 확인할 수 있습니다.
Read now
Unlock full access






