May 2026
Intermediate
378 pages
5h 49m
Korean
이 작품은 AI를 사용하여 번역되었습니다. 여러분의 피드백과 의견을 환영합니다: translation-feedback@oreilly.com
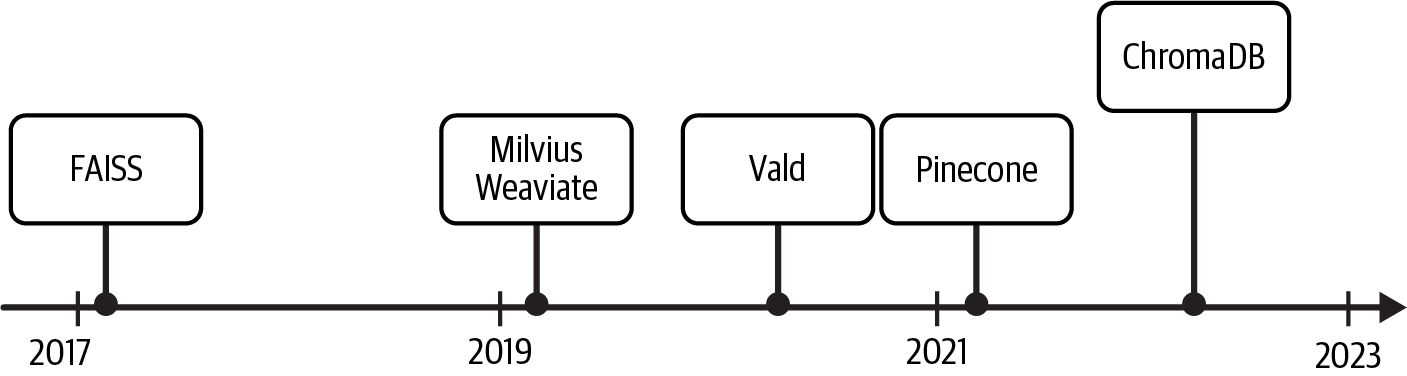
벡터 데이터베이스는 특히 LLMs의 등장 이후 급속도로 인기를 얻고 있습니다. 그림 6-1은 가장 널리 사용되는 벡터 데이터베이스 몇 가지와 출시 시기를 보여줍니다.
FAISS는 2017년에 출시되었으며, 이어 2019년에 Milvus와 Weaviate, 2020년에 Vald, 2021년에 Pinecone, 2023년에 Chroma가 출시되었습니다. 동시에 PostgreSQL 및 Elasticsearch와 같은 기존 데이터베이스들도 기존 플랫폼에 벡터 검색 기능을 추가했습니다. 즉, 기존 SQL 또는 NoSQL 데이터베이스가 이미 벡터 검색을 지원한다면 기술 스택에 전용 벡터 데이터베이스를 반드시 추가할 필요는 없습니다.
이 장에서는 FAISS, Chroma, PostgreSQL을 포함하여 벡터 연산을 지원하는 인기 있는 라이브러리와 데이터베이스를 소개합니다. 독자들은 자신의 요구 사항에 맞는 적절한 벡터 스토어를 선택하는 방법, 유사도 검색을 구현하는 방법, 인덱싱 기법을 사용하여 성능을 최적화하는 방법을 배우게 될 것입니다.
이 장 전체에 걸쳐 “유사도 검색”과 “시맨틱 검색”이라는 용어를 모두 접하게 될 것입니다. 유사도 검색은 벡터 공간에서 서로 가까운 벡터를 찾는 기술적 작업을 의미합니다. 시맨틱 검색은 정확한 키워드 대신 의미를 기반으로 검색하는 사용자 중심의 기능을 설명합니다. 시맨틱 검색은 유사도 검색을 기본 메커니즘으로 사용하여 구현됩니다.
이 장의 모든 코드 예제는 책의 GitHub 저장소에서 확인할 수 있습니다.
는 과도한 설계나 잘못된 기술 스택에 얽매이지 않으면서, RAG 워크로드와 팀, 인프라에 적합한 벡터 데이터베이스를 선택해야 합니다.
다음의 의사결정 경로를 사용하여 선택지를 현실적인 1~2개로 좁히십시오. RAG 애플리케이션을 위한 벡터 데이터베이스를 평가하고 선택하려면 다음 단계를 따르십시오:
벡터 검색은 전처리, 실험 또는 오프라인 파이프라인에서만 사용됩니까? 아니면 사용자에게 서비스를 제공하는 라이브 애플리케이션의 일부입니까?
벡터 검색이 라이브 시스템의 일부가 아니라면, 다음과 같은 벡터 라이브러리나 인-파일 벡터 스토어를 사용하십시오:
파이프라인 및 실험용 FAISS 또는 Annoy
로컬 RAG 프로토타입용 Chroma
벡터 검색이 라이브 애플리케이션의 일부라면 2단계로 진행하십시오.
임베딩이 비즈니스 데이터, 사용자, 문서 또는 권한과 함께 저장되어야 합니까?
그렇다면, 이미 ...
Read now
Unlock full access






