May 2026
Intermediate
378 pages
5h 49m
Korean
이 작품은 AI를 사용하여 번역되었습니다. 여러분의 피드백과 의견을 환영합니다: translation-feedback@oreilly.com
측정할 수 없는 것은 개선할 수 없습니다. 검색 매개변수를 조정하거나 prompts를 수정하거나 모델을 교체할 때, 이러한 변경이 도움이 되는지 아니면 해가 되는지를 알려주는 지표가 필요합니다. 평가 없이는 최적화는 추측에 불과합니다.
RAG 평가는 기존의 머신러닝(ML)과는 다른 접근 방식을 필요로 합니다. 기존 ML에서는 라벨이 지정된 데이터에서 패턴을 학습하도록 모델을 훈련시킨 다음, 이를 본 적 없는 예시에 일반화할 수 있는지 테스트합니다. 반면 RAG 시스템은 학습하지 않고, 정보를 검색하고 생성합니다. 파운데이션 모델은 이미 다양한 작업에 걸쳐 일반화 능력을 갖추고 있습니다. 따라서 핵심은 모델이 패턴을 학습했는지 여부가 아니라, 올바른 정보를 검색하고 유용한 답변을 생성했는지 여부입니다.
이러한 차이는 평가 방식에 영향을 미칩니다. 핵심 과제는 테스트 질문이 시스템 데이터에 단어 하나하나까지 그대로 나타나지 않으면서도 현실적인 사용자 의도를 포괄하고, 동시에 이용 가능한 지식으로 답변할 수 있어야 한다는 점입니다. RAG에서 좋은 일반화 능력이란 동일한 근본적인 질문에 대한 다양한 표현을 처리할 수 있는 것을 의미합니다. 정확한 문구보다 의도가 더 중요합니다. 이는 테스트 설계에 영향을 미치는데, 기존 라벨링된 예제를 분할하는 대신 실제 쿼리를 재구성해야 합니다.
그림 10-1은 이 문제를 잘 보여줍니다. 축구 규칙만 알고 있는 시스템에 철학적인 질문을 던지면 무의미한 평가 결과가 나옵니다.
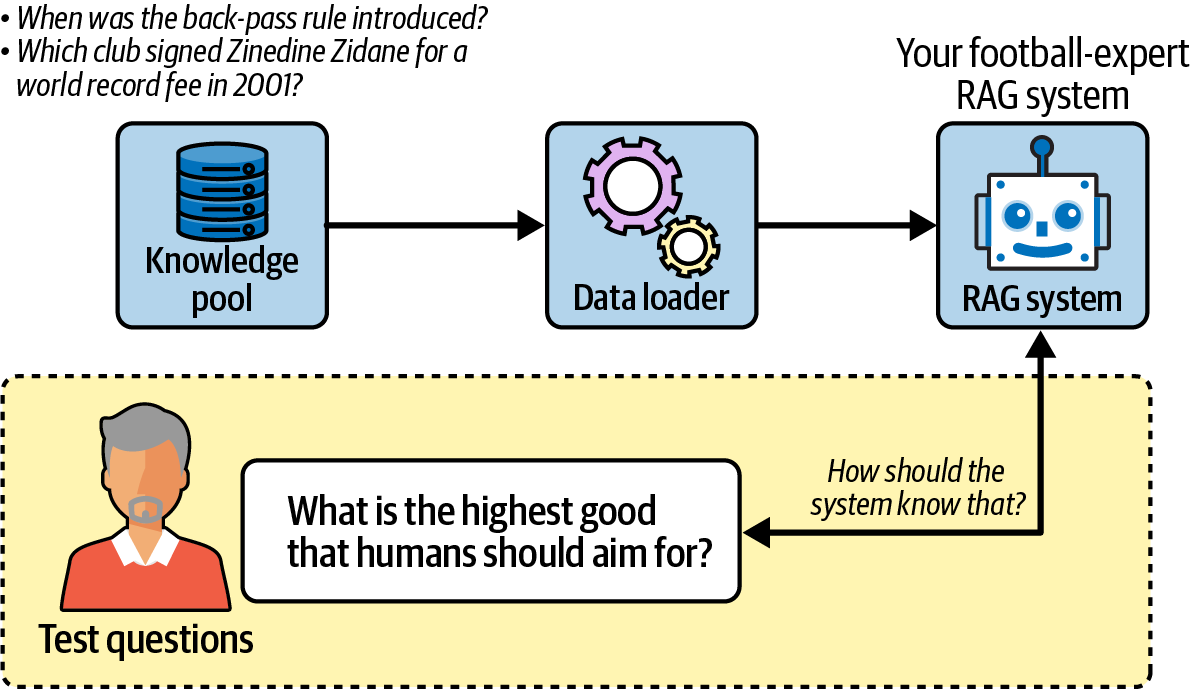
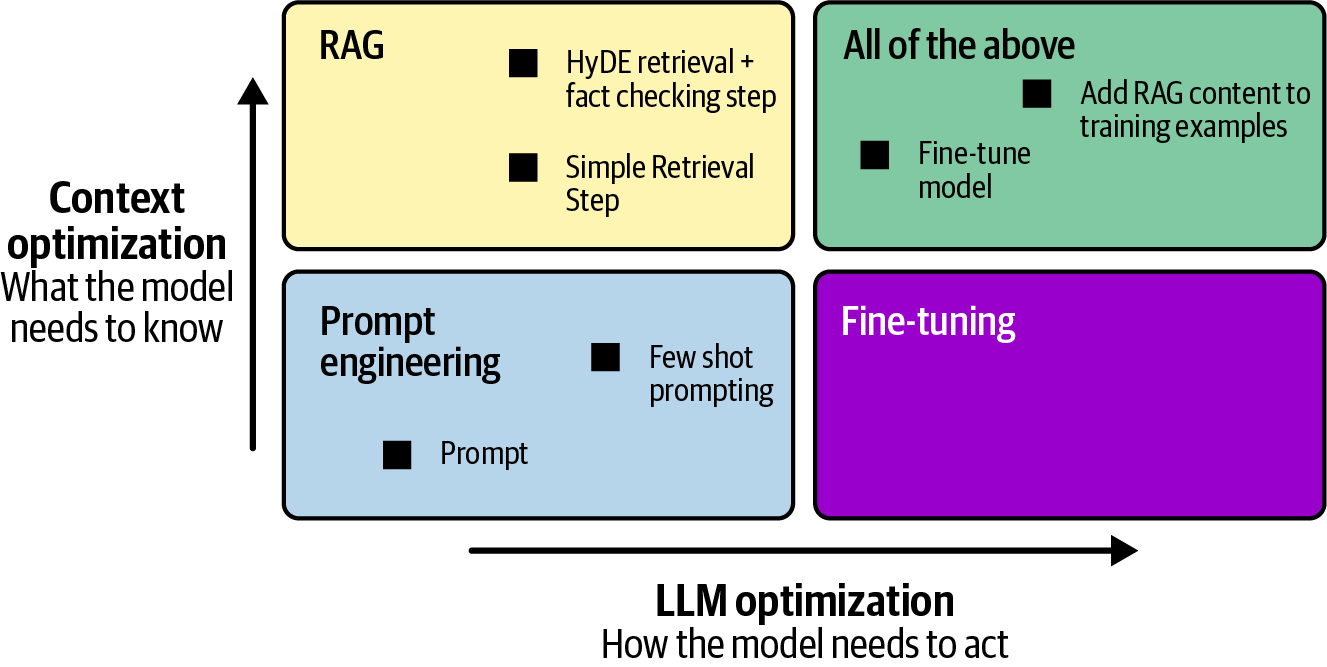
그림 10-2는 RAG 성능을 향상시키기 위한 두 가지 차원을 보여줍니다: RAG 파이프라인 자체(검색, 청킹, 재순위 지정)와 생성 모델(, 미세 조정 또는 prompt 엔지니어링을 통해). 조정할 수 있는 요소가 너무 많기 때문에, 어떤 변경 사항이 실제로 정확도와 관련성을 향상시키는지 판단하기 위해 평가 지표가 필요합니다.
언어는 주관적이기 때문에 생성 결과를 평가하는 것은 어려운 과제입니다. 가장 확장성이 뛰어난 접근 방식은 LLMs이 다른 LLM의 출력을 평가하도록 하는 것으로, 마치 작가가 자신의 작품을 검토하는 것과 유사합니다. 이 접근 방식은 그 한계를 이해하고 평가를 신중하게 설계할 때 효과적입니다.
실제 RAG 시스템의 경우, 아키텍처는 단순한 검색기-생성기 ...
Read now
Unlock full access






