May 2026
Intermediate
378 pages
5h 49m
Korean
이 작품은 AI를 사용하여 번역되었습니다. 여러분의 피드백과 의견을 환영합니다: translation-feedback@oreilly.com
그래프 RAG는 기본 검색 기능을 확장하여 그래프 탐색( )을 도입함으로써, 고립된 텍스트 임베딩의 의미적 유사성에만 의존하는 대신 엔티티와 관계의 네트워크를 탐색할 수 있게 해줍니다.
기본적인 RAG 시스템은 문서를 조각으로 분할하여 임베딩한 후, 벡터 검색을 통해 관련 콘텐츠를 도출합니다. 벡터 검색은 각 조각을 독립된 단위로 취급하므로, 더 넓은 서사 속에서 조각들이 어떻게 연결되는지 인식하지 못합니다. 정보가 긴 문서의 여러 부분에 분산되어 있거나 여러 출처의 데이터가 필요한 경우, 이러한 접근 방식은 관련 맥락을 놓치게 됩니다. 섹션 간에 존재하는 종속성, 참조, 관계가 상실되는 것입니다.
그래프 RAG는 이러한 격차를 해소합니다. 텍스트를 단순히 임베딩으로 저장하는 대신, 엔티티를 추출하고 이들 간에 명시적인 관계를 형성하며, 이 그래프 구조를 벡터 인덱스와 결합합니다. 이를 통해 더 풍부하고 정밀한 맥락을 생성하며, 엔티티 간의 명시적인 연결을 보존합니다.
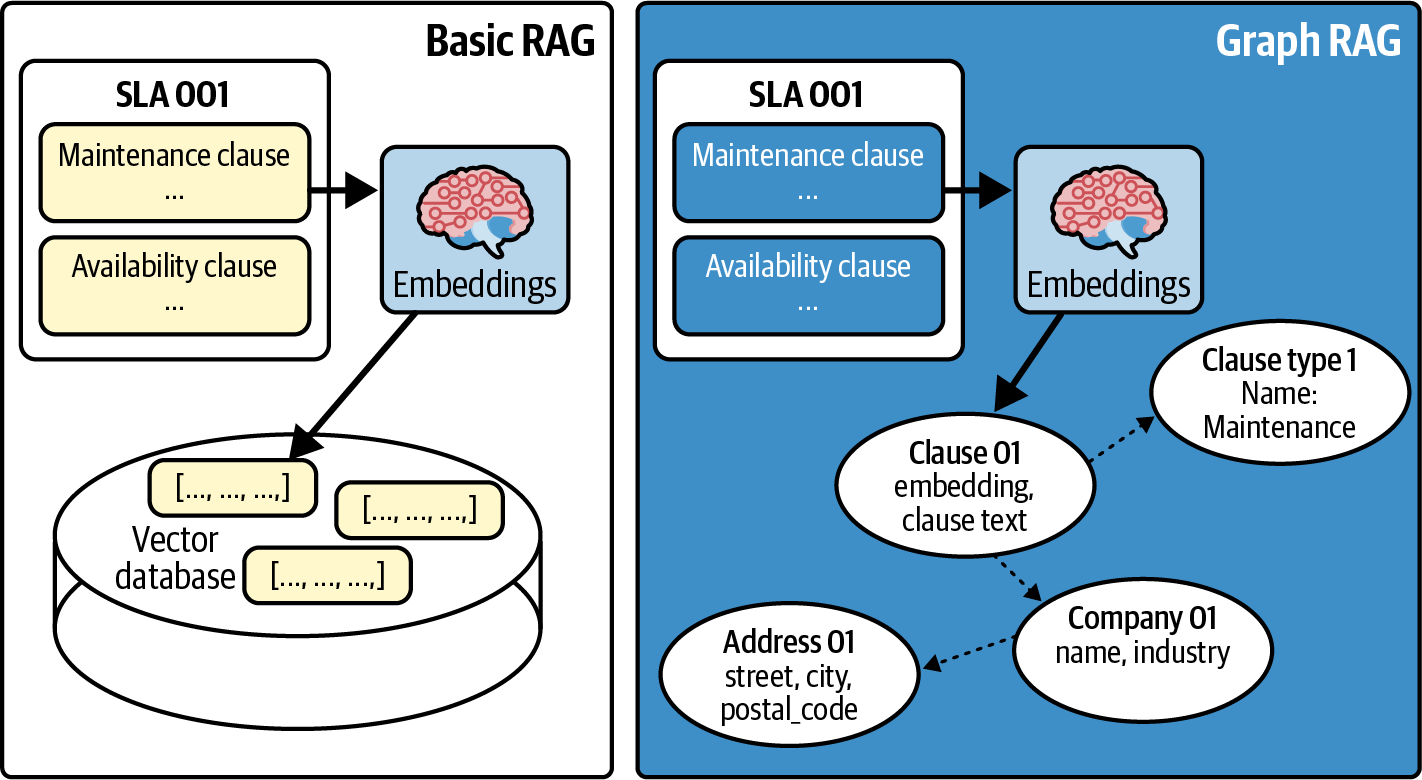
그림 9-1은 계약서 문서 데이터를 사용하여 기본 RAG와 그래프 RAG의 차이를 보여줍니다. 기본 RAG 설정에서 시스템은 고립된 임베딩 벡터 풀을 유지합니다. 반면 그래프 RAG에서는 모든 텍스트 스니펫이 주변 구조에 고정됩니다. 각 조항은 해당 조항 유형, 회사, 주소, 그리고 해당 조항이 유래한 서비스 수준 계약(SLA)과 연결됩니다. 이러한 구조적 컨텍스트는 모델이 관련 텍스트를 찾을 뿐만 아니라, 그 텍스트가 어디에 속하는지 진정으로 이해하는 데 도움을 줍니다.
그래프 RAG 시스템을 구축하려면 기존의 검색기를 그래프 데이터베이스로 대체합니다. 이 장에서는 모든 그래프 예제에 Neo4j를 사용합니다.
그래프가 채워지면 검색 흐름은 일반적으로 다음 네 단계를 따릅니다:
초기 검색: 벡터 검색이나 전체 텍스트 검색 중 하나로 시작하여 관련 노드를 식별합니다. 이 노드들이 앵커 포인트 역할을 합니다.
그래프 확장: 앵커 노드에서 시작하여, 일반적으로 1~2단계의 경로를 통해 그래프를 탐색하며 관련 노드와 에지를 수집합니다.
(선택 사항) 필터링 및 순위 지정: 확장된 결과 집합을 정제하여 의미 있는 맥락을 제공하는 노드만 남깁니다.
컨텍스트 조립 및 생성: 원본 앵커 텍스트와 연결된 컨텍스트를 모두 LLM에 입력합니다.
이 프로세스는 의미적 매칭과 구조적 추론을 결합하여 의미와 연결 관계를 모두 반영하는 맥락을 생성합니다. 그림 9-2는 주요 검색 프로세스를 보여줍니다.
이 장에서는 첫 번째 지식 그래프를 구축하고, 문서의 ...
Read now
Unlock full access






