May 2026
Intermediate
378 pages
5h 49m
Korean
이 작품은 AI를 사용하여 번역되었습니다. 여러분의 피드백과 의견을 환영합니다: translation-feedback@oreilly.com
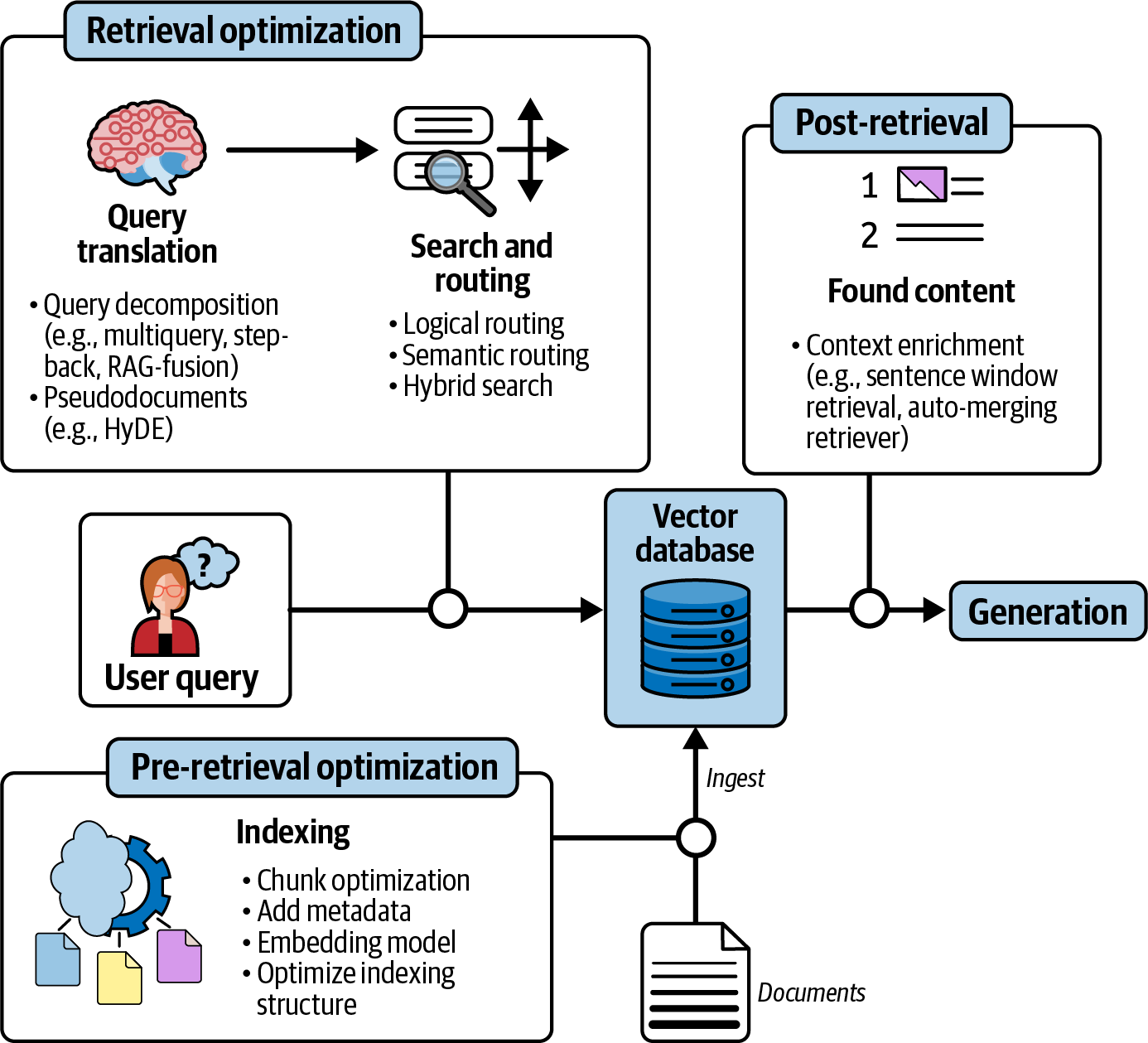
검색( ) 개선 검색 단계는 RAG 시스템의 정확도와 관련성을 높이는 가장 효과적인 방법입니다. 맞춤형의 고효율 시스템을 구축하려면 견고한 툴킷이 필요합니다. 이 장에서는 기본적인 벡터 검색을 넘어서는 고급 검색 기법을 소개합니다. 그림 7-1은 검색 전 단계와 검색 단계를 최적화하기 위한 기법들의 개요를 보여줍니다.
실제 RAG 워크플로는 일반적으로 사용 사례에 따라 이러한 기술 중 여러 가지를 결합합니다. 그림 7-2는 여러 단계와 고급 검색 기술을 결합한 워크플로 예시를 보여줍니다. 이 워크플로는 다음 세 가지 핵심 단계를 보여줍니다: (1) 복잡한 쿼리를 집중적인 하위 쿼리로 분할하고, (2) 각 하위 쿼리를 적절한 도구 또는 데이터 소스로 라우팅하여 관련 정보를 검색하며, (3) 답변들을 종합적으로 추론하여 포괄적인 응답을 생성합니다.
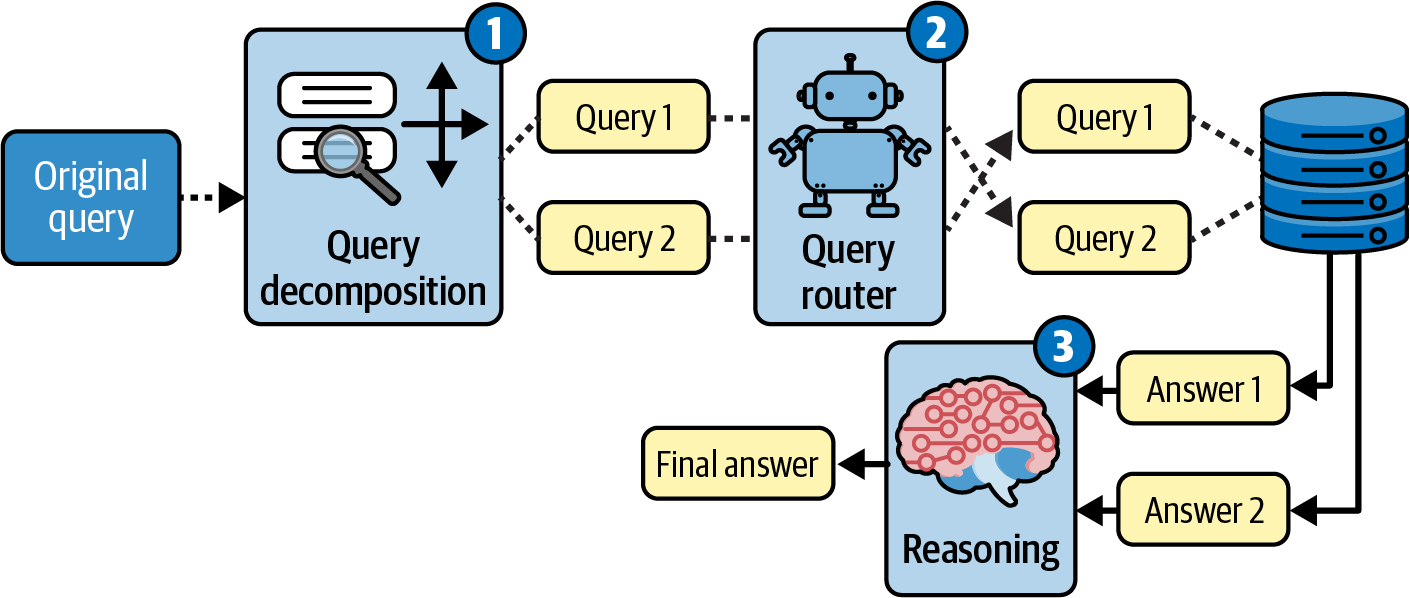
이 장에 소개된 방법들을 워크플로를 개선하고 더 나은 검색 결과를 얻기 위해 조합할 수 있는 구성 요소로 생각하십시오. 사용 사례에 가장 적합한 방식으로 적용할 수 있는 고급 검색 기법 도구 모음이 필요합니다.
표 7-1은 이 장에서 다룬 7가지 기법을 요약한 것입니다. 각 기법을 이해하고, 특정 데이터 세트와 작업에 어떤 기법이 적합한지 결정해야 합니다.
| 기법 | 설명 | 레시피 참조 |
|---|---|---|
메타데이터 필터링 |
사용자에 대해 알고 있는 정보를 바탕으로 메타데이터를 사용하여 검색 결과 필터링하기 |
|
다중 쿼리 검색 |
더 관련성 높은 문서를 찾기 위해 동일한 prompt의 여러 버전을 생성하기 |
|
쿼리 라우팅 시스템 |
질문 라우팅 시스템을 사용하여 질문에 답하기 위해 사용할 최적의 데이터 소스나 도구를 식별하기 |
|
자동 병합 검색기 |
관련 데이터를 그룹화하여 더 크고 의미 있는 텍스트 단위를 추출하기 |
|
문장 창 검색 |
검색된 텍스트에 맥락을 더하기 위해 인접한 문장 포함하기 |
|
가상 문서 임베딩(HyDE) |
검색 결과 개선을 위한 가상 문서 생성 |
|
쿼리 분해 |
복잡한 쿼리를 더 간단한 하위 쿼리로 분해하기 |
|
재순위 지정 |
LLMs을 통해 검색된 문서의 관련성을 검토 및 평가하기 |
이 장의 모든 코드 예제는 책의 GitHub 저장소에서 확인할 수 있습니다.
Read now
Unlock full access






