September 2021
Intermediate to advanced
392 pages
6h 8m
Japanese
本章では、パイプラインにデータセットを取り込む方法を紹介します。取り込んだデータセットは、図3-1に示した、さまざまなコンポーネントで利用できます。なお、本章の内容は、基本的なTFXの設定とML MetadataStoreの準備が完了していることを前提としています。
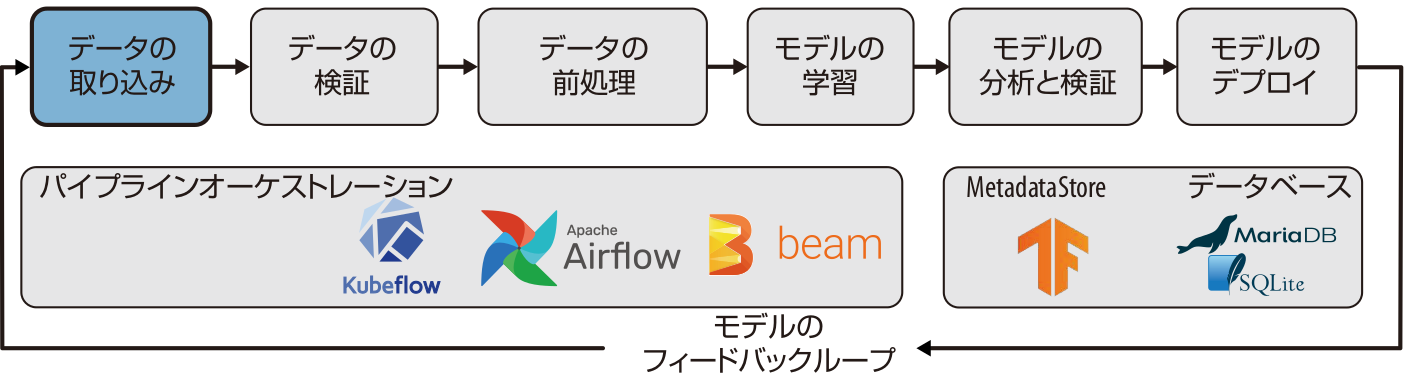
図3-1 機械学習パイプラインにおけるデータの取り込み
TFXには、ファイルやサービスからデータを取り込むためのコンポーネントがあります。最初に、データ取り込みの基本的な概念やデータセットを学習用と評価用に分割する方法を説明します。次に、複数のデータエクスポートを1つのデータセットに結合する方法を示します。最後に、構造化データ、テキストデータ、画像データを取り込むための戦略について説明します。ここで紹介する戦略は、過去の事例でその有用性が証明されたものです。
データの取り込みでは、データファイルを読み込むか、Google Cloud BigQueryなどの外部サービスにパイプラインを実行するためのデータをリクエストします。取り込んだデータセットは次のコンポーネントへ渡す前に、学習用と検証用のように複数に分割します。そして、分割したデータセットをTFRecordファイルに変換します。このファイルには、tf.train.Example型で表現されたデータを格納します。
TFRecordは大規模なデータセットのストリーミングに最適化された軽量フォーマットです。実際には、ほとんどのTensorFlowユーザーはシリアル化されたプロトコルバッファのデータをTFRecordファイルに保存しています。しかし、TFRecordファイル形式は、次に示すように、あらゆるバイナリデータをサポートしています。 ...
Read now
Unlock full access






