September 2021
Intermediate to advanced
392 pages
6h 8m
Japanese
これまでに、データに関する統計量の確認や正しい特徴への変換、モデルの学習をしてきました。いよいよモデルを本番環境にデプロイする時が来たのでしょうか。私見ですが、モデルをデプロイする前に、モデルの性能を詳細に分析し、本番環境へデプロイ済みのモデルより性能が改善されているか確認するステップが必要だと考えています。図7-1に、パイプラインにおけるこれらのステップの立ち位置を示します。
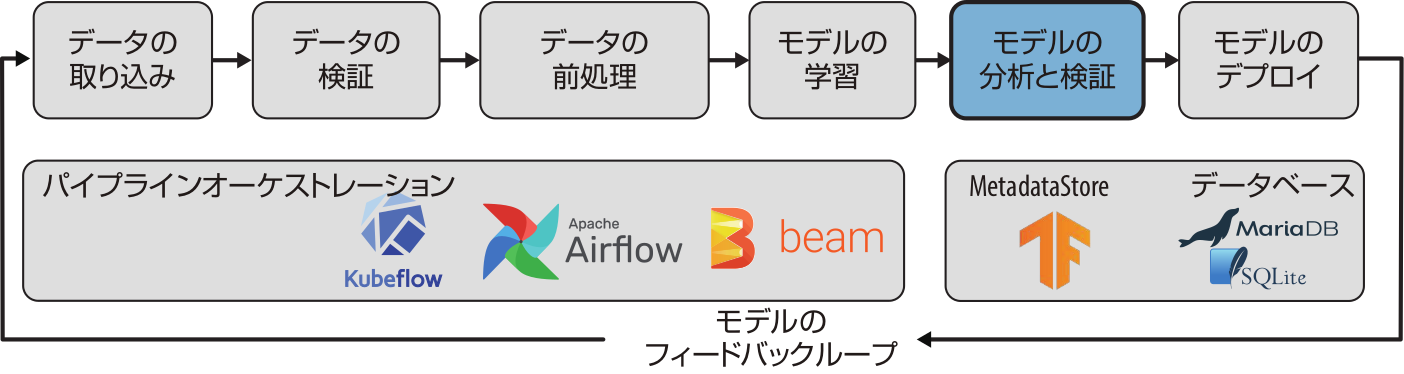
図7-1 機械学習パイプラインにおけるモデル分析と検証
モデルの学習中は、評価セットを使って性能を計測し、さまざまなハイパーパラメータを試して最高性能を引き出そうとします。ただ、学習中に使用する指標は1つだけのことが多く、正解率を使うのが常です。
機械学習パイプラインを構築する際には、複雑なビジネス上の質問に答えようとしたり、複雑な実世界のシステムをモデル化しようとしたりすることがよくあります。モデルがその質問に答えられるかどうかを判断するには、1つの指標だけでは十分でないことがよくあります。これは、データセットが不均衡であったり、モデルの予測による影響がグループ間で偏っている場合、とくに当てはまります。
加えて、指標1つで評価セット全体の平均的な性能を表すため、重要な詳細を覆い隠してしまうことがあります。たとえば、モデルが人々に関するデータを扱っている場合、次のようなことを気にしたほうがよいはずです。
Read now
Unlock full access






