September 2021
Intermediate to advanced
392 pages
6h 8m
Japanese
機械学習モデルを本番に投入するためのスムーズなパイプラインができたので、一度だけ実行して終わらせたくはありません。一度デプロイしたモデルは、そのまま放っておいてはダメなのです。新しいデータを収集すると、データの分布が変化し(「4章 データ検証」)、モデルはドリフトします(「7章 モデル分析と検証」)。そういうわけで、何よりも大切なことは、パイプラインを継続的に改善することです。
図13-1に示すように、何らかのフィードバックを与えることで、パイプラインはライフサイクルに変化します。モデルの予測は、新しいデータの収集につながり、その結果、モデルは継続的に改善されるようになります。
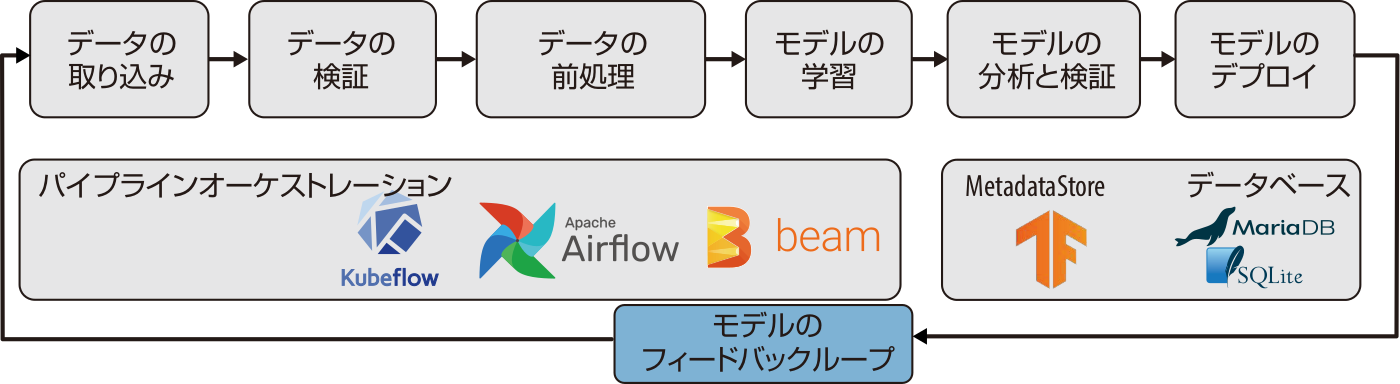
図13-1 機械学習パイプラインにおけるモデルフィードバック
新しいデータを収集しないと、時間の経過とともに入力データは変化するため、モデルの予測能力低下につながる可能性があります。実のところ、モデルをデプロイすると、ユーザー体験が変化するため、学習データが変化すると考えられます。たとえば、動画推薦システムでは、モデルの推薦する動画を気に入れば、ユーザーの選択する動画はこれまでとは違ったものになるでしょう。フィードバックループは、モデルを更新するための新しいデータを収集するのに役立ちます。とりわけ、推薦システムや予測入力など、パーソナライズされたモデルで効果的です。
この時点で、パイプラインの他の箇所がロバストに構成されていることが非常に重要です。新しいデータの投入は、データの統計量がデータ検証で設定した制限から外れた場合や、モデルの統計量がモデル分析で設定した境界から外れた場合、パイプラインの失敗につながります。そうなると、モデルの再学習や特徴エンジニアリングなどのイベントを起動できます。これらのいずれかのイベントが発生した場合、新しいモデルには新しいバージョン番号を付与する必要があります。 ...
Read now
Unlock full access






