Beyond encoding data in a textual format, an XML document doesn’t do much of anything on its own. The true power of XML lies in the tools that process it. In this section, we take a quick tour of the interesting ways to work with XML documents using tools and technologies widely available today from a number of different vendors.
Since an XML document is just text, you can:
These and other tools can treat an XML file the same as any other text file for common development tasks.
More sophisticated XML editing tools read an XML DTD to understand the lexicon of legal tag names for a particular XML vocabulary, as well as the various constraints on valid element combinations expressed in the DTD. Using this information, the tools assist you in creating and editing XML documents that comply with that particular DTD. Many support multiple views of your XML document including a raw XML view, a WYSIWYG view, and a view that augments the WYSIWYG display by displaying each markup tag.
As an example, this book was created and edited entirely in XML using SoftQuad’s XMetal 1.0 product in conjunction with the DocBook DTD, a standard XML vocabulary for authoring technical manuals. Figure 1.2 shows what XMetal looks like in its WYSIWYG view with tags turned on, displaying an earlier version of the XML source document for this very chapter.
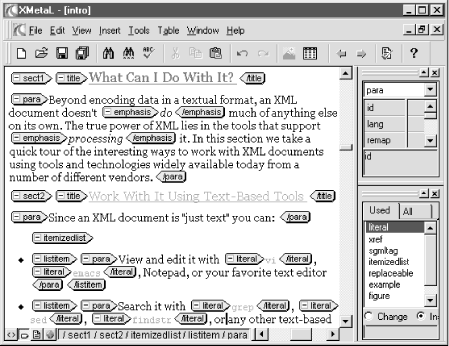
If the XML documents you edit look more like a data structure than a technical manuscript, then a WYSIWYG view is likely not what you want. Other DTD-aware editors like Icon Software’s XML Spy and Extensibility’s XML Instance present hierarchical views of your document more geared toward editing XML-based data structures like our transaction example in Example 1.1, or an XML-based purchase order.
An XML document can be sent as easily as any other text document over the Web using any of the Internet’s widely adopted protocols, such as:
By convention, when documents or other resources are exchanged using
such protocols, each is earmarked with a standard content type
identifier that indicates the kind of resource being exchanged. For
example, when a web server returns an HTML page to a browser, it
identifies the HTML document with a content type of
text/html
. Similarly, every time your browser
encounters an <img> tag in a page, it makes an HTTP request to
retrieve the image using a URL and gets a binary
document in response, with a content type like
image/gif
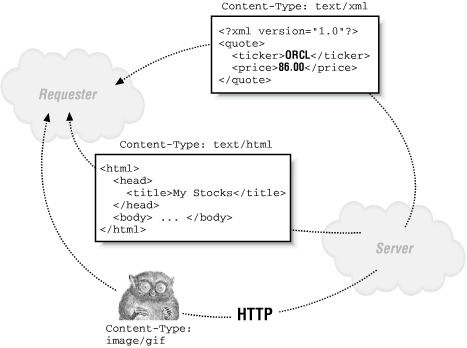
. As illustrated in Figure 1.3, you can easily exchange XML documents over
the Web by leveraging this same mechanism. The standard content type
for XML documents is text/xml.
The act of exchanging XML documents over the Web seems straightforward when XML is viewed as just another content type, but it represents something very powerful. Since any two computers on the Web can exchange documents using the HTTP protocol, and since any structured data can be encoded in a standard way using XML, the combination of HTTP and XML provides a vendor-neutral, platform-neutral, standards-based backbone of technology to send any structured data between any two computers on the network. When XML documents are used to exchange data in this way, they are often called XML datagrams . Given the rapid increase in the number of portable electronic devices sporting wireless Internet connectivity, these XML datagrams can be easily shuttled between servers and cell phones or personal data assistants (PDAs) as well.
The XML datagrams exchanged between clients and servers on the Internet become even more interesting when the content of the XML datagram is generated dynamically in response to each request. This allows a server to provide an interesting web service, returning datagrams that can answer questions like these:
- What are the French restaurants within one city block of the Geary Theatre?
<?xml version="1.0"?> <RestaurantList> <Restaurant Name="Brasserie Savoy" Phone="415-123-4567"/> </RestaurantList>
- When is Lufthansa Flight 458 expected to arrive at SFO today?
<?xml version="1.0"?> <FlightArrival Date="06-05-2000"> <Flight> <Carrier>LH</Carrier> <Arrives>SFO</Arrives> <Expected>14:40</Expected> </Flight> </FlightArrival>- What is the status of the package with tracking number 56789?
<?xml version="1.0"?> <TrackingStatus PackageId="56789"> <History> <Scanned At="17:45" On="06-05-2000" Comment="Williams Sonoma Shipping"/> <Scanned At="21:13" On="06-05-2000" Comment="SFO"/> <Scanned At="04:13" On="06-06-2000" Comment="JFK"/> <Scanned At="06:05" On="06-06-2000" Comment="Put on truck"/> <Delivered At="09:58" On="06-06-2000" Comment="Received by Jane Hubert"/> </History> </TrackingStatus>
Since XML is just text, it is straightforward to generate XML dynamically using server-side programs in virtually any language: Java, PL/SQL, Perl, JavaScript, and others. The first program you learn in any of these languages is how to print out the text:
Hello, World!
If you modify this example to print out instead:
<?xml version="1.0"?> <Message>Hello, World!</Message>
then, believe it or not, you have just mastered the basic skills needed to generate dynamic XML documents! If these dynamic XML documents are generated by a server-side program that accesses information in a legacy database or file format, then information that was formerly locked up in a proprietary format can be liberated for Internet-based access by simply printing out the desired information with appropriate XML tags around it.
As we saw above, an XML document can use either an ad hoc vocabulary of tags or a formal vocabulary defined by a DTD. Common questions developers new to XML ask are:
- What are some existing web sites that make XML available?
The nicely organized http://www.xmltree.com site provides a directory of XML content on the Web and is an interesting place to look for examples. The http://www.moreover.com site serves news feeds in XML on hundreds of different news topics.
- How do I find out whether there is an existing standard XML DTD for what I want to publish?
There is at present no single, global registry of all XML DTDs, but the following sites are good places to start a search: http://www.xml.org, http://www.schema.net, and http://www.ebxml.org.
- If I cannot find an existing DTD to do the job, how do I go about creating one?
There are a number of visual tools available for creating XML DTDs. The XML Authority tool from Extensibility (see http://www.extensibility.com) has proven itself invaluable time and time again during the creation of this book, both for viewing the structure of existing DTDs and for creating new DTDs. An especially cool feature is its ability to import an existing XML document and “reverse engineer” a DTD for it. It’s not always an exact science—since the example document may not contain occurrences of every desired combination of tags—but the tool does its best, giving you a solid starting point from which you can easily begin fine-tuning.
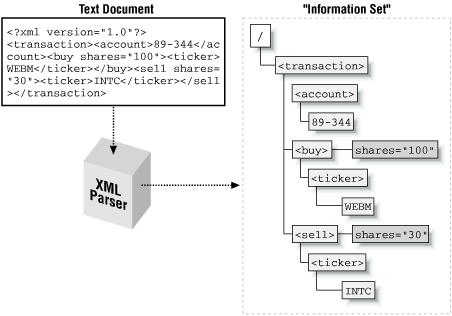
We’ve seen that XML documents can represent tree-structured data by using tags that contain other nested tags as necessary. Because of this nesting, just looking at an XML document’s contents can be enough for a human to understand the structured information it represents:
<?xml version="1.0"?> <transaction><account>89-344</account><buy shares="100"><ticker exch="NASDAQ">WEBM</ticker></buy><sell shares="30"><ticker exch="NYSE">GE</ticker></sell></transaction>
This is especially true if the document contains extra whitespace (line breaks, spaces, or tabs) between the tags to make them indent appropriately, as in Example 1.1. For a computer program to access the structured information in the document in a meaningful way, an additional step, called parsing , is required. By reading the stream of characters and recognizing the syntactic details of where elements, attributes, and text occur in the document, an XML parser exposes the hierarchical set of information in the document as a tree of related elements, attributes, and text items. This logical tree of information items is called the XML document’s information set, or infoset for short. Figure 1.4 shows the information set produced by parsing our <transaction> document.
When you work with items in the logical, tree-structured infoset of an XML document, you work at a higher level of abstraction than the physical “text and tags” level. Instead, you work with a tree of related nodes: a root node, element nodes, attribute nodes, and text nodes. This is conceptually similar to the “tables, rows, and columns” abstraction you use when working with a relational database. Both abstractions save you from having to worry about the physical “bits and bytes” storage representation of the data and provide a more productive model for thinking about and working with the information they represent.
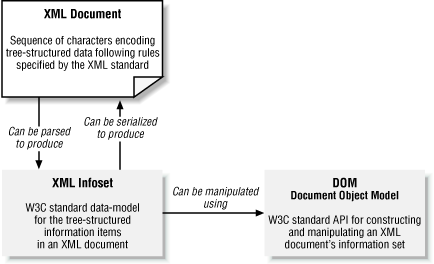
Once an XML document has been parsed to produce its infoset of element, attribute, and text nodes, you naturally want to manipulate the items in the tree. The W3C provides a standard API called the Document Object Model (DOM) to access the node tree of an XML document’s infoset. The DOM API provides a complete set of operations to programmatically manipulate the node tree, including navigating the nodes in the hierarchy, creating and appending new nodes, removing nodes, etc. Once you’re done making modifications to the node tree, you can easily save, or serialize the modified infoset back into its physical text representation as text and tags again. Figure 1.5 illustrates the relationship between an XML document, the infoset it represents, and the DOM API.
Often you will want to interrogate an XML document to select
interesting subsets of information. The W3C standard
XML Path Language
(XPath) provides a simple, declarative language to accomplish the
job. Let’s look at some simple examples of this declarative
syntax using our <transaction> document from Example 1.1.
Leveraging your familiarity with the hierarchical path notation for
URLs and files in directories, an XPath expression allows you to
select the <ticker> symbol of the <buy> request in the
<transaction> by using the expression:
/transaction/buy/ticker
To select the number of shares in the <sell>
request in the <transaction>, you can use the expression
/transaction/sell/@shares, prefixing the name of
the attribute you want with an at-sign. Filter predicates can be
added at any level to refine the information you will get back from
the selection. For example, to select the ticker symbol for
<buy> requests over 50 shares, you can use
the expression
/transaction/buy[@shares>50]/ticker.
As illustrated in Figure 1.6, XPath queries select information from the logical tree-structured data model presented by an XML document’s infoset, not from its raw text representation.

One of the most useful things you can do with XML is transform it from one tree-based structure to another. This comes in handy when you want to:
Convert between XML vocabularies used by different applications
Present an XML document’s data by transforming it into HTML or another format that’s appropriate to the user or device requesting the data
Fortunately, the W3C has again provided a companion standard called XSLT (the XML Stylesheet Language for Transformations) to make this task declarative. XSLT was originally conceived as a language to transform any XML document into a tree of formatting objects from which high-quality printed output could be easily rendered. The W3C XSL Working Group recognized early that this XML transformation facility would be an important subset of functionality in its own right, so they formally separated the XSLT language from the XSL formatting objects specification. This allowed the XSLT language to perform any useful XML-to-XML transformation. These origins help explain why the definition of an XML transformation is known as a stylesheet .
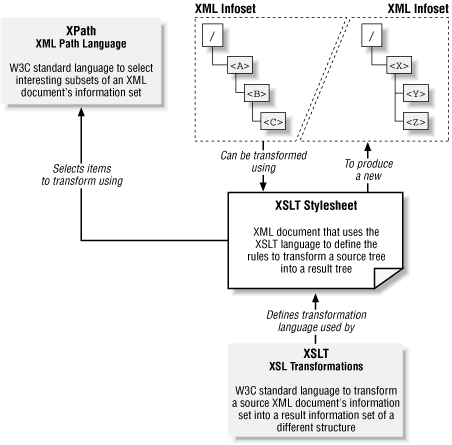
An XSLT stylesheet is an XML document that uses the XSLT language’s vocabulary to describe the transformation you want to perform. The stylesheet consists of transformation instructions, which use XPath expressions to select interesting information items from the infoset of a source document and specify how to process the results of these selections to construct an infoset for a +++result document with a different structure. Figure 1.7 highlights this relationship between XSLT and XPath and illustrates how the transformation is carried out on the logical source tree and result tree.
Let’s assume that on receiving our transaction datagram, our
application needs to turn around and send an appropriate datagram to
the NASDAQ trading system to complete the trade. Of course, the
datagram we send to NASDAQ must use the XML vocabulary that the
NASDAQ trading system understands. The relevant datagram using the
<nasdaq-order> vocabulary
might look like this:
<?xml version="1.0"?>
<nasdaq-order clientid="123">
<trans type="buy">
<security>WEBM</security>
<shares>100</shares>
</trans>
</nasdaq-order>We can create an XSLT stylesheet that selects any <buy>
requests in the <transaction> for stocks on the NASDAQ exchange
and constructs the appropriate <trans>, <security>, and
<shares> elements as nested “children” of a
<nasdaq-order> in the result. Example 1.2
shows what this stylesheet looks like.
Example 1-2. XSLT Stylesheet to Transform Between XML Vocabularies
<?xml version="1.0"?>
<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:output indent="yes"/>
<xsl:template match="/">
<nasdaq-order clientid="123">
<!-- Use XPath to select buy transactions for stocks on the NASDAQ -->
<xsl:for-each select="/transaction/buy[ticker/@exch='NASDAQ']">
<trans type="buy">
<security><xsl:value-of select="ticker"/></security>
<shares><xsl:value-of select="@shares"/></shares>
</trans>
</xsl:for-each>
</nasdaq-order>
</xsl:template>
</xsl:stylesheet>Notice that we use the XPath expression
/transaction/buy[ticker/@exch='NASDAQ'] to select
the <buy> elements that satisfy our criteria
as part of the transformation. Given a source tree structure like the
one for our incoming transaction document and an XSLT stylesheet like
Example 1.2 describing the transformation, an
XSLT processor
carries out the transformation to
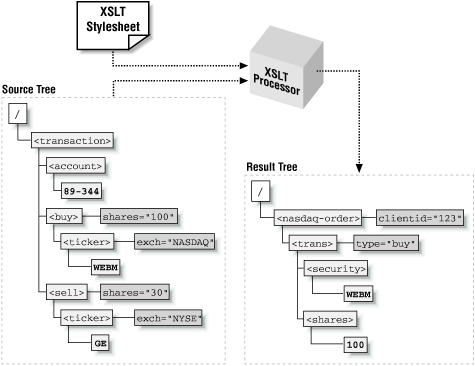
produce the result tree as illustrated in Figure 1.8.
Tip
Appendix C, illustrates how all the basic standards in the XML family relate to one another. It’s a summary of what we’ve seen in this chapter, all in a single diagram for easy reference.
Get Building Oracle XML Applications now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

