October 2018
Beginner
362 pages
9h 32m
English
If we wanted to classify the expression of a person during a video, or perhaps label a scene at any given time, or even for speech-to-text recognition, we would use a many-to-many architecture. Many-to-many architectures take in a variable's length sequence while also outputting a variable length sequence:
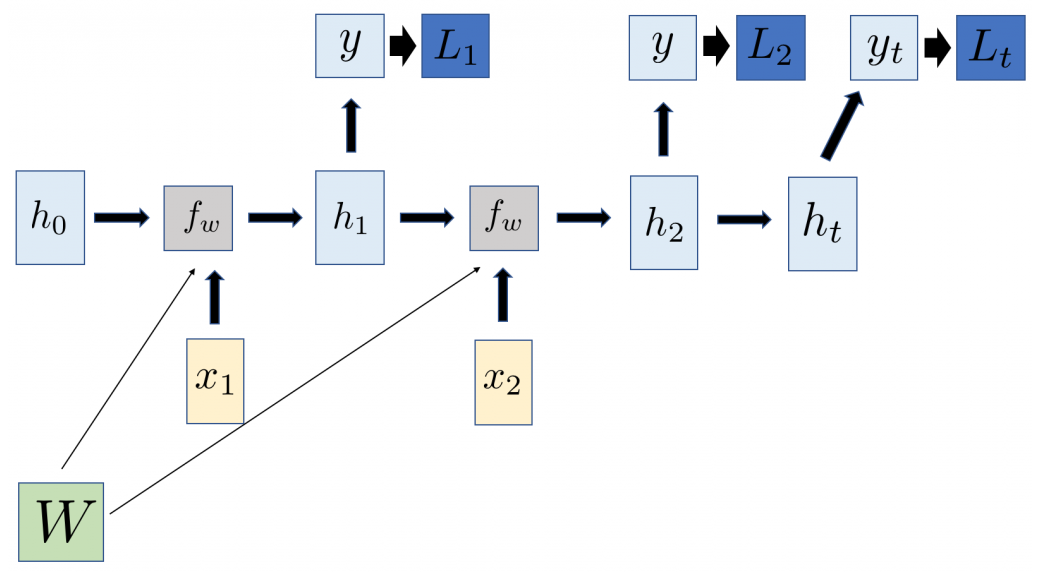
An output vector is computed at every step of the process, and we can compute individual losses at every step in the sequence. Frequently, we utilize a softmax loss for explicit labeling tasks. The final loss will be the sum of these individual losses.
Read now
Unlock full access






