October 2018
Beginner
362 pages
9h 32m
English
The actor network is also called the target policy network. The actor is trained by utilizing gradient descent that has been mini-batched. Its loss is defined with the following function:
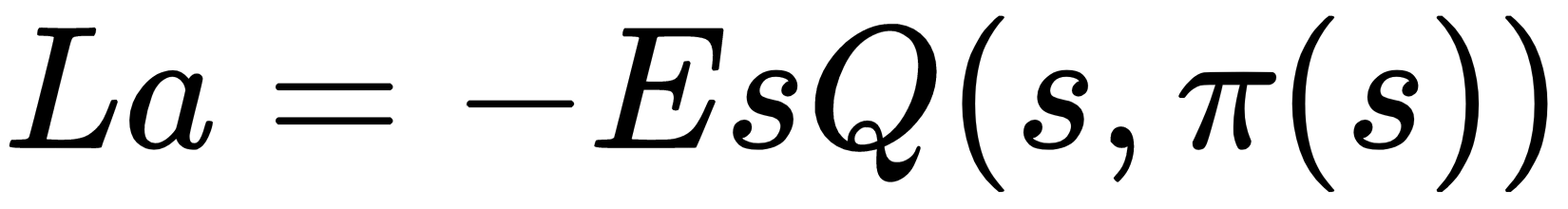
Here, s represents a state that has been sampled from the replay buffer.
Read now
Unlock full access






