For autoencoders, we use a different network architecture, as shown in the following figure. In the first couple of layers, we decrease the number of hidden units. Halfway, we start increasing the number of hidden units again until the number of hidden units is the same as the number of input variables. The middle hidden layer can be seen as an encoded variant of the inputs, where the output determines the quality of the encoded variant:
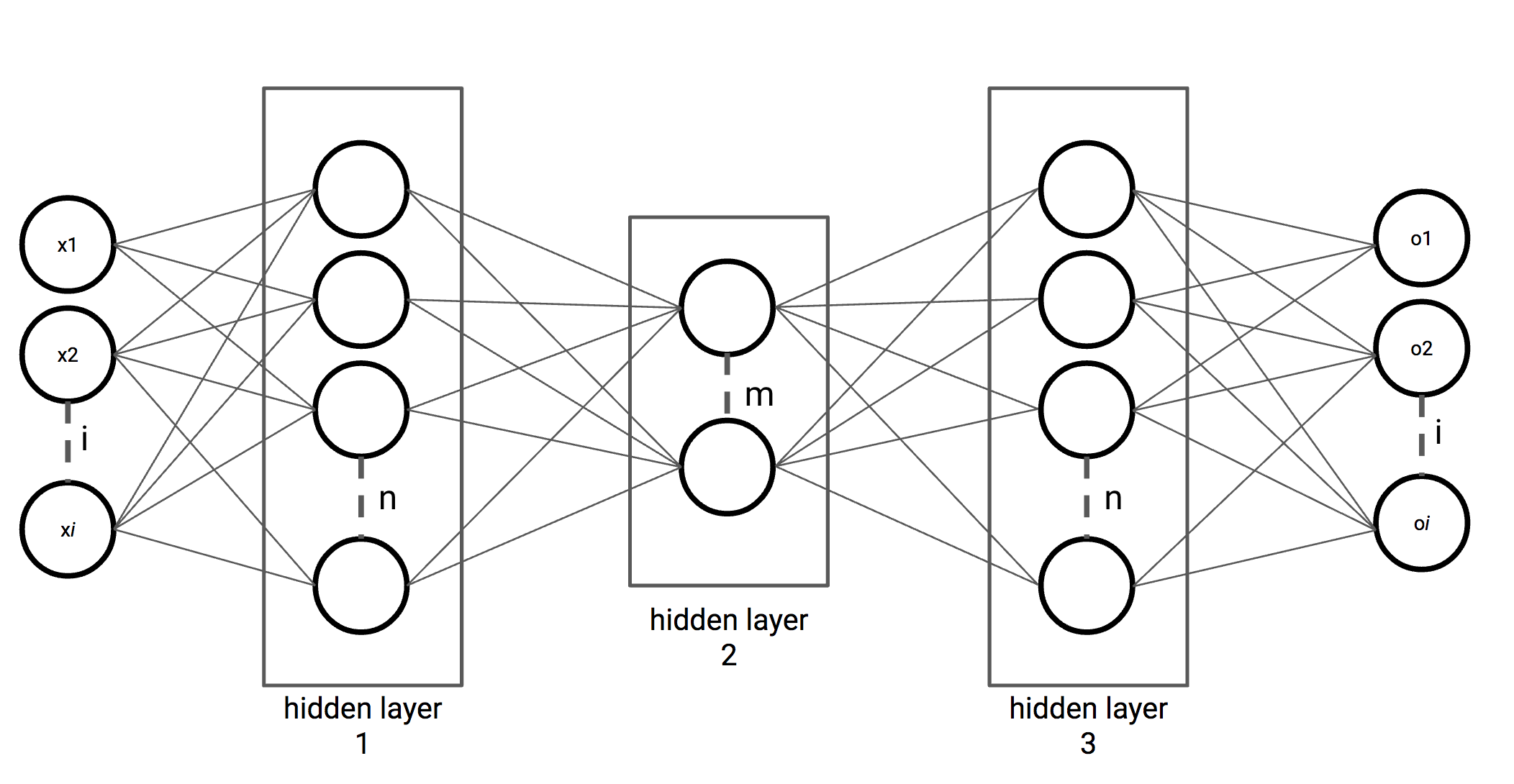
Figure 2.13: Autoencoder network with three hidden layers, with m < n
In the next recipe, we will implement an autoencoder in Keras to decode Street View House Numbers (SVHN) from ...

