November 2025
Intermediate to advanced
1060 pages
18h 47m
Japanese
この作品はAIを使って翻訳されている。ご意見、ご感想をお待ちしている:translation-feedback@oreilly.com
本章では、まずシングル命令マルチスレッド(SIMT)実行モデルと、ワープ、スレッドブロック、グリッドがGPUベースのアルゴリズムをストリーミングマルチプロセッサ(SM)にマッピングする仕組みを復習する。
現代のNVIDIA GPUにおけるSIMT実行モデルを再確認し、ワープ、スレッドブロック、グリッドがSMにどのようにマッピングされるかを説明する。次にCUDAプログラミングパターンに深く入り、オンチップメモリ階層(レジスタファイル、共有/L1、L2、HBM3e)について議論し、GPUの非同期データ転送機能(Tensor Memory Accelerator(TMA)やTensor Core演算のアキュムレータとして機能するTensor Memory(TMEM)を含む)を実演する。
さらに、ルーフライン分析を用いて演算制約型カーネルとメモリ制約型カーネルを識別する手法を紹介する。これにより、現代のGPUシステムを理論上のピークスループット限界まで押し上げる基礎が得られる。
CPUが低遅延のシングルスレッド性能のために を最適化するのとは異なり、GPUは数千のスレッドを並列実行するために設計されたスループット最適化プロセッサである。CPUとGPU間の単純なCUDAプログラミングフローを図6-1に示す。
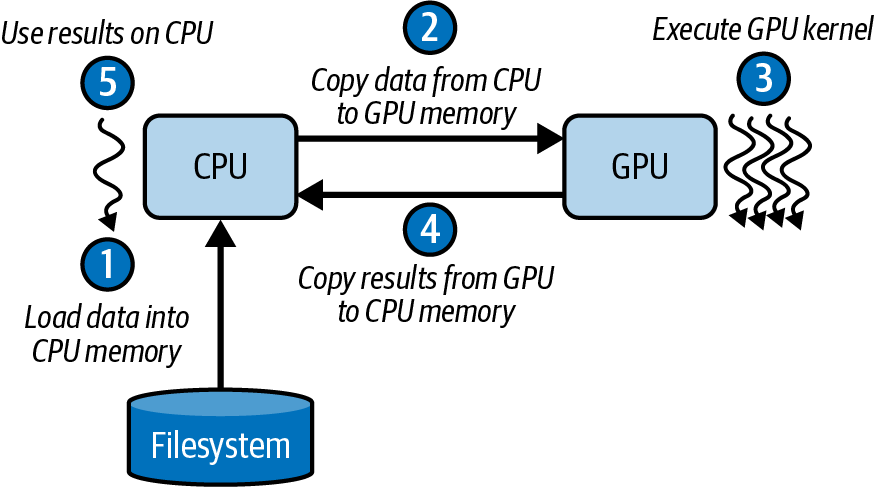
最初にホストがデータをCPUメモリにロードする。次にCPUからGPUメモリへデータをコピーする。GPUメモリ内のデータでGPUカーネルを呼び出した後、CPUは結果をGPUメモリからCPUメモリへコピーする。こうして結果はCPUに戻り、さらなるプロセスが行われる。
GPUは、図6-1で説明したCPU-GPU間データ転送のような遅延を隠蔽するために、大規模並列性に依存している。各GPUは多数のSMで構成されており、これらはCPUコアに大まかに類似しているが、並列処理向けに最適化されている。Blackwellでは、各SMは最大64のワープ(32スレッドグループ)を追跡できる。
各GPUには多数のSMが含まれる。これらはCPUコアとの類似性があり、スループット最適化が図られている。現代のGPUでは、各SMが最大64のワープ(2,048スレッド)を同時に追跡する。Blackwell GPUはSMあたり64Kの32ビットレジスタ(合計256KB)と、SMあたり合計256KBのL1キャッシュ/共有メモリを備える。このSRAMのうち最大228KB(実使用可能227KB)を、SMごとにユーザ管理型共有メモリとして設定できる。単一のスレッドブロックは最大227KBの動的共有メモリをリクエスト可能(228KBのうち1KBはCUDA用に予約されている)。これらがSMのGPU高水準並列性を支える。
Blackwell SM内では、複数のワープスケジューラが利用可能なパイプラインに命令を発行する。4つの独立したワープスケジューラにより、毎サイクル最大4つのワープが利用可能なパイプラインに命令を発行できる。さらに各スケジューラはデュアル発行をサポートし、ワープごとに2つの独立した命令(例:1つの算術演算と1つのメモリオペレーション)を発行できる。ただしデュアル発行は同一ワープ内でのみ可能であり、ワープ間では行えない。 ...
Read now
Unlock full access






