November 2025
Intermediate to advanced
1060 pages
18h 47m
Japanese
この作品はAIを使って翻訳されている。ご意見、ご感想をお待ちしている:translation-feedback@oreilly.com
大規模なLLM推論クラスターを運用するには、すべてが想定通りに動作していることを確認する監視およびデバッグツールが必要だ。これらはまた、パフォーマンスが目標値から外れた際にボトルネックを迅速に特定するのにも役立つ。
本章では、NVIDIA Nsight SystemsによるプロファイリングやPrometheus/Grafanaによるクラスタ全体のテレメトリなど、これらの複雑なシステムを監視・デバッグする方法を示す。また、GPU使用率、メモリ圧力、テール遅延パーセンタイル、キャッシュヒット率、トークン単位のタイミングなど、主要なメトリクスの収集と解釈方法も説明する。これらは推論エンジンの性能最適化を導く指針となる。
次に運用パフォーマンス調整について議論する。GPU使用率の最適化、推論遅延の低減、大規模クラスタリングでのスループット向上など、実稼働環境で実証済みの手法を含む。これには計算とコミュニケーションのオーバーラッピング、リクエストのスケジューリングとバッチ処理、NVLink・NVSwitch・InfiniBandといった高速相互接続の有効活用といったテクニックが含まれる。
さらに、推論のためのリアルタイム量子化テクニックも比較する。具体的には、汎用後処理量子化(GPTQ)や活性化値を考慮した重み量子化(AWQ)といった実装手法を用いた、モデルを8ビットや4ビット精度に圧縮する方法だ。その過程で、重みのみの量子化とのトレードオフと、重み・活性化値の両方を量子化する手法のトレードオフについても議論する。サービス提供パイプラインにおける量子化の適用について、メモリ使用量の削減とスループットの向上を実現しつつ、モデルの精度を維持するための実践的なガイダンスを提供する。
最後に、低レベルな性能調整を補完するアプリケーションレベルの最適化を検討する。これにはプロンプト圧縮、プレフィックスキャッシュ、重複排除、クエリルーティング(例:フォールバックモデル)、部分出力ストリーミングなどの戦略が含まれる。
現代のLLM推論エンジンには多くの可動部分がある——特に分散型プリフィルとデコードでは。典型的なリクエストのライフサイクルは図16-1に示すように多くの構成要素を伴う。
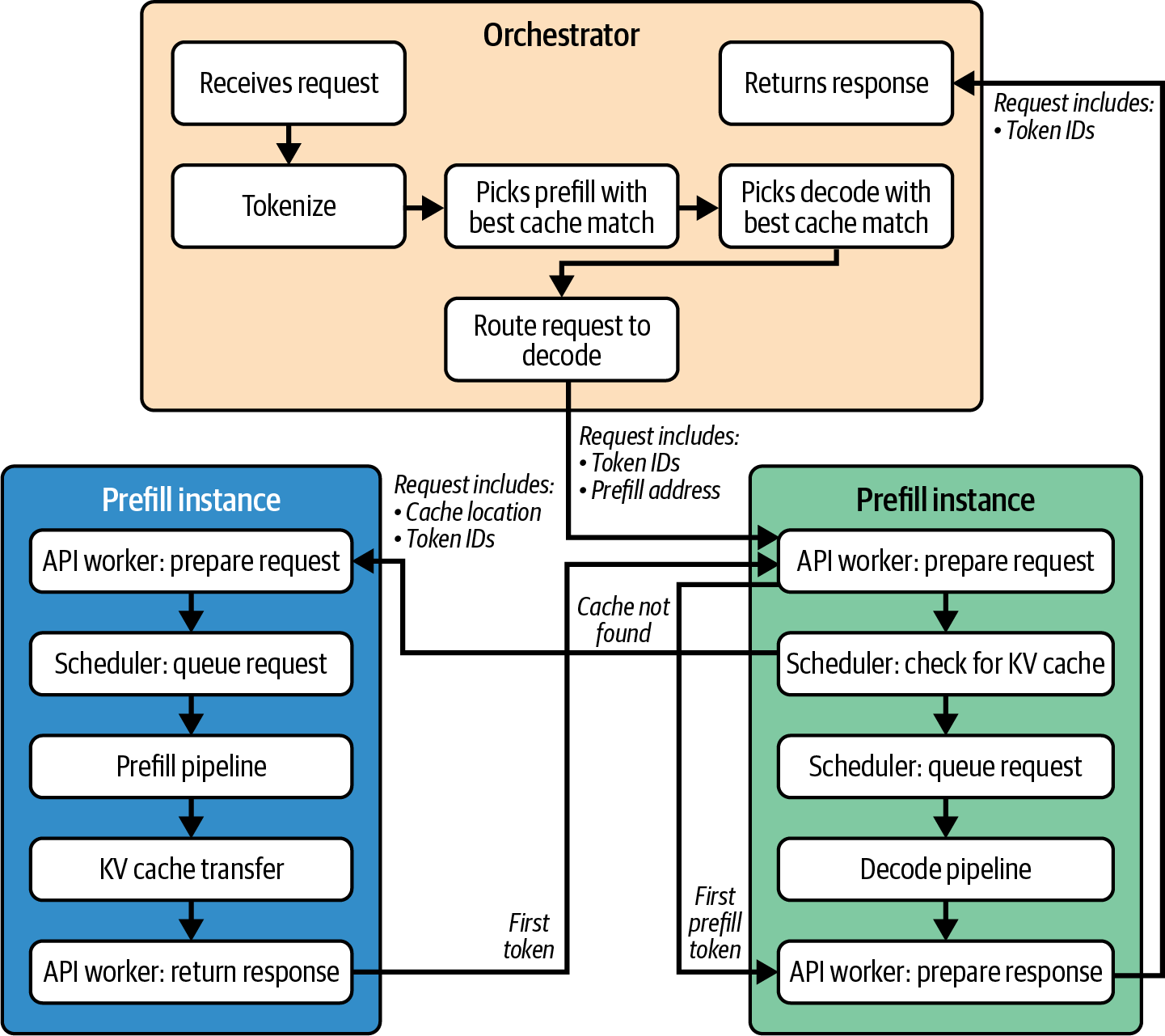
このような複雑さゆえに、推論パフォーマンスのチューニングワークフローは非常に反復的だ。慎重な調整と継続的な検証が必要となる。
まず、メトリックを観察し、GPUの完全な活用不足や予想以上の遅延など、現在のボトルネックを特定する。次に、「バッチサイズを増やす」や「操作Xのコミュニケーションと計算のオーバーラップを増やす」といった改善仮説を立てる。その後、修正を実装し仮説をテストする。
理想的には、ステージング環境で代表的なワークロードを用い、プロファイリングツールを用いて修正をテストし、変更が期待通りに動作することを検証すべきだ。例えば、操作が適切なメモリと演算のオーバーラップを示していることを確認できる。 ...
Read now
Unlock full access






