November 2025
Intermediate to advanced
1060 pages
18h 47m
Japanese
この作品はAIを使って翻訳されている。ご意見、ご感想をお待ちしている:translation-feedback@oreilly.com
本章では、人間とAIが連携してAIシステムの性能を最適化する方法を示す、様々な事例と将来の動向をまとめる。具体的には、AIが低レベルのGPUコードのファインチューニングを支援し、手作業で作成したカーネルよりも高速に動作するカーネルを生成できる。
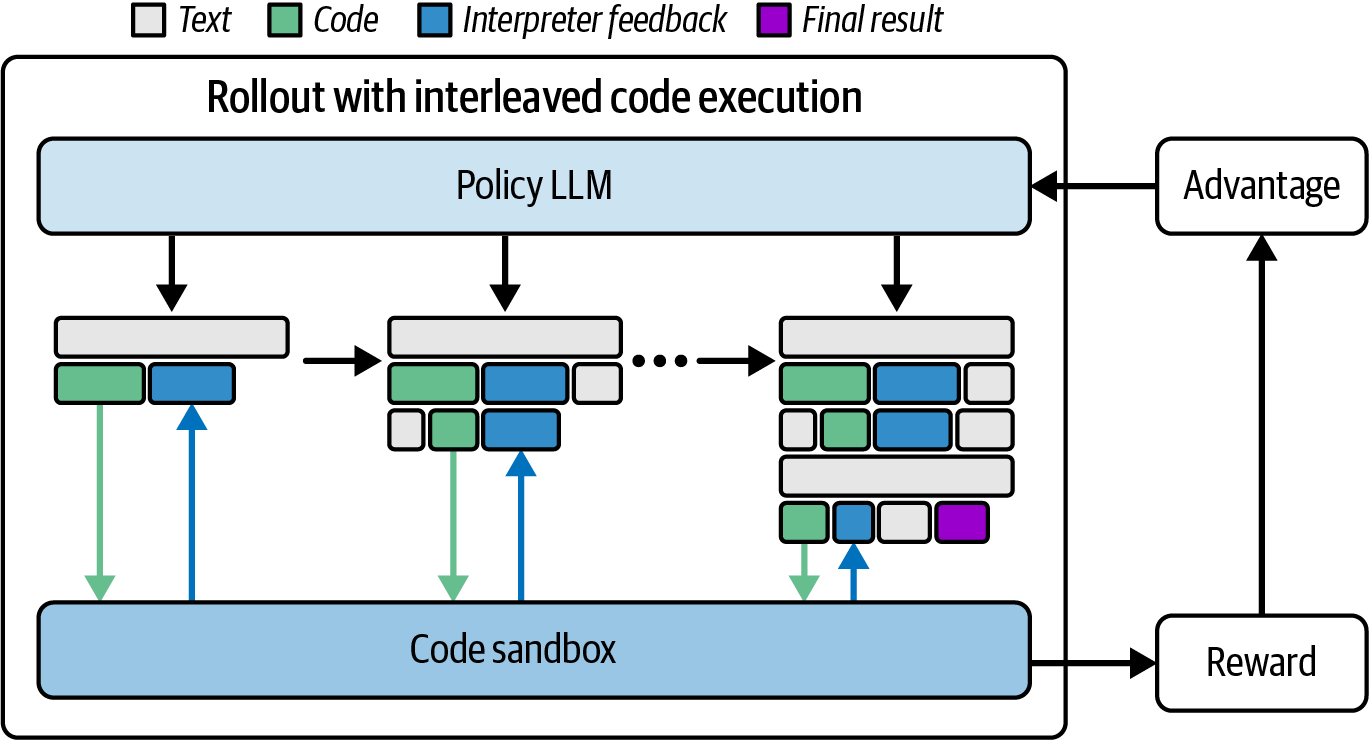
より広いコンテキストでは、これらの事例は、行列乗算のような中核的な演算においても、アルゴリズムの革新が新たなハードウェア導入と類似性の性能向上をもたらし得ることを示している。高レベルな観点では、一連の強化学習ロールアウト(反復処理など)からの報酬フィードバックを利用するワークフローを考えてみよう。図20-1に示すように、これは環境にとって最適なGPUカーネルコードを発見するのに役立つ。
こうしたAI支援アプローチは、性能向上、トレーニング時間の短縮、運用コストの削減に寄与する。また、より大規模なモデルを小規模システムに効率的にデプロイすることを可能にし、AIの将来的な進歩を解き放つ。言い換えれば、これはAIがより優れたAIの作成を支援する仕組みだ。我々はこれを歓迎する!
AI最適化は必ずしもコードレベルで行われるわけではない。 時には最適化はアルゴリズムや数学の領域に深く踏み込む。画期的な例が2022年のDeepMindのAlphaTensorプロジェクトで、AIを用いて新しい汎用行列乗算(GEMM)テクニックを発見した。
GEMMは、ほぼ全てのモデルトレーニングと推論ワークロードを支える中核的な演算だ。GEMMの効率性がわずかに向上するだけで、AI分野全体に多大な影響を与える可能性がある。AlphaTensorは、高速アルゴリズムの探索を単一プレイヤーゲームとして形式化し、強化学習を用いて多様な可能性を探索した。
驚くべき結果として、当時存在するあらゆる人間が考案したメソッドよりも優れた行列乗算の公式を発見した。例えば図20-2に示すように、2×2行列向けのストラッセンの有名な二次以下アルゴリズムを再発見しただけでなく、より大きな行列サイズ向けに改良を加えたのである。
しかし真の証明は、これらのアルゴリズムを実際のハードウェアでテストした時に得られた。AlphaTensorはNVIDIA Volta V100 GPU世代に特化した手法を発見し、当時標準だったNVIDIA V100時代のcuBLASライブラリよりも大規模行列の乗算を10~20%高速化した。GEMM性能で10~20%の高速化は極めて大きい。これは、モデルごとの順伝播と逆伝播で、追加で10~20%の無料計算能力を獲得するようなものだ。
通常、このような性能向上は新世代ハードウェアの導入か、数か月にわたる低レベルなCUDAチューニングによって達成される。しかし今回は、AIが比較的短期間で数学的に優れた手法を発見したのである。 ...
Read now
Unlock full access






