November 2025
Intermediate to advanced
1060 pages
18h 47m
Japanese
この作品はAIを使って翻訳されている。ご意見、ご感想をお待ちしている:translation-feedback@oreilly.com
これまで、単一カーネルでSMを稼働させるため、カーネル内部のツール(cuda::pipeline 、ダブルバッファリング、ワープ特殊化(ローダー/演算/ストアーワープ)、永続カーネル、DSMEM/TMAを用いたスレッドブロッククラスタ)に焦点を当ててきた。本章ではそれらのカーネルを維持しつつ、CUDAストリーム、イベント、ストリーム順序メモリ割り当て器を用いて、カーネル間およびバッチ間でパイプライン化する手法を示す。要するに、第10章ではカーネル内部の遅延を隠蔽することに焦点を当てた。本章では、カーネル間およびGPUとホスト間の遅延を隠蔽する方法を示す。
この種のカーネル間並行処理は、実世界のワークロードにおいてGPUの全エンジンを稼働状態に保つために不可欠である。現代のGPUでピーク利用率を達成するには、GPUの演算エンジンとダイレクトメモリアクセス(DMA)エンジンを並列に稼働させ続ける必要がある。
CUDA ストリームはこのカーネル間並行処理の基盤を提供する。非同期メモリ操作、細粒度の同期、CUDA グラフ(本章で簡単に紹介し、次章で詳しく扱う)を組み合わせることで、ホスト側のストールを回避する高効率なパイプラインを構築できる。
CUDAストリームとは、 操作(カーネル起動、メモリコピー、メモリ割り当て)のシーケンスであり、発行された順序で実行される。図11-1に示すように、CPUからGPUへ2つのストリームを使用して5つのカーネルを起動すると考える。
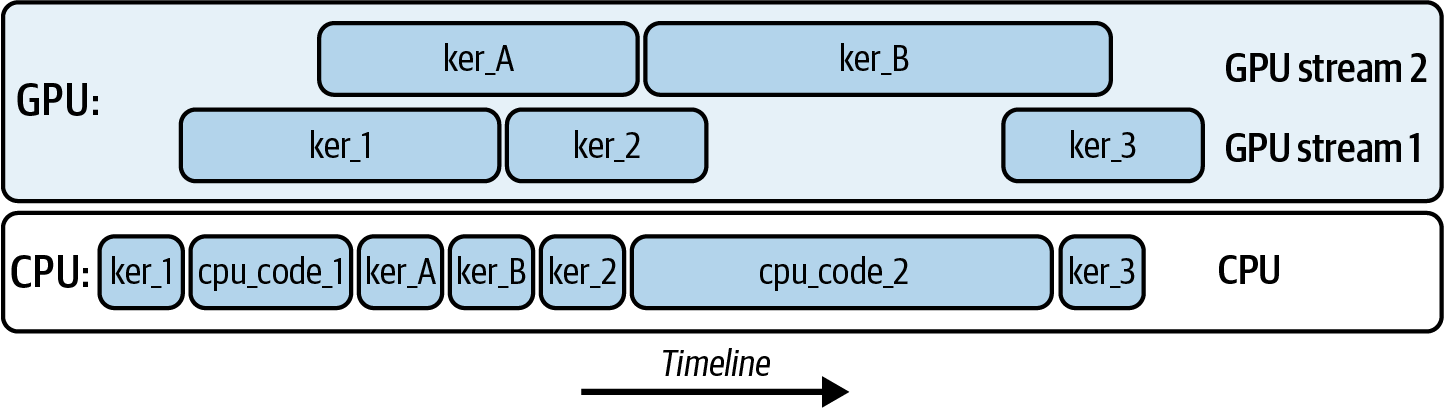
ここでは、ker_A とker_B がストリーム2で実行され、ker_1 、ker_2 、ker_3 がストリーム1で実行されている。ハードウェアリソースが許容する限り、全てのカーネルは互いに、またCUDAストリーム間で重なり合うことができる。
CPUは、ストリームが非同期にカーネル操作を実行している間も、作業(cpu_code_1 とcpu_code_2) )を継続できる。これら5つのカーネルを2つのCUDAストリーム上で起動するコードは次の通りだ:
#include<cstdio>#include<cuda_runtime.h>__global__voidker_A(){/* ... do some work ... */}__global__voidker_B(){/* ... do some work ... */}__global__voidker_1(){/* ... do some work ... */}__global__voidker_2(){/* ... do some work ... */}__global__voidker_3(){/* ... do some work ... */}intmain(){// 1) ...
Read now
Unlock full access






