November 2025
Intermediate to advanced
1060 pages
18h 47m
Japanese
この作品はAIを使って翻訳されている。ご意見、ご感想をお待ちしている:translation-feedback@oreilly.com
第13章では、PyTorchベースのトレーニングと推論ワークロードを最適化・調整する複数の方法について論じた。PyTorchコンパイラについて触れ、コードをほとんど変更せずにパフォーマンスを向上させるために、カーネル融合やその他のカーネルレベルのテクニックを自動化する仕組みを説明した。
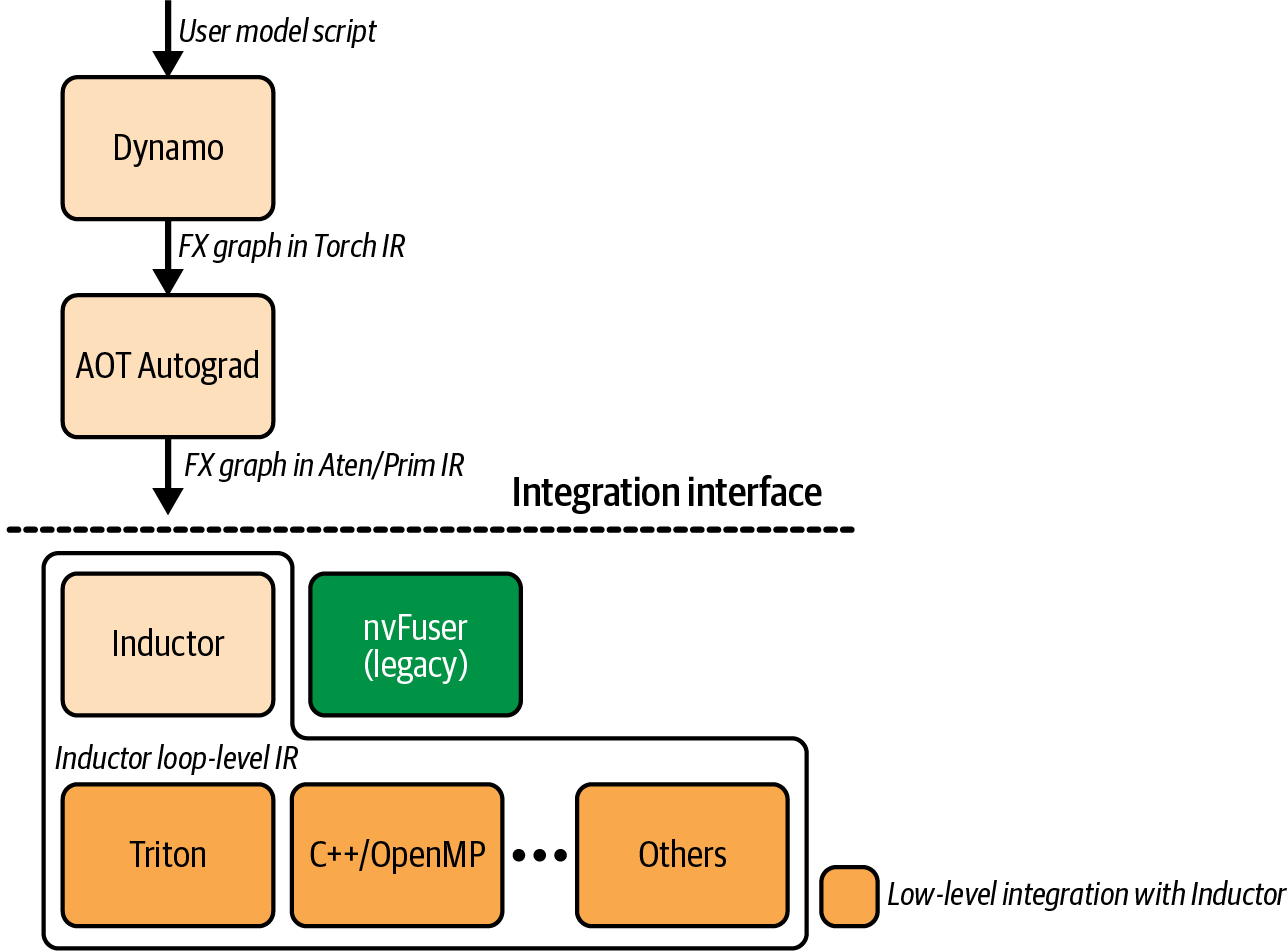
本章では、TorchDynamo、Ahead-of-Time Autograd(AOT Autograd)、PrimTorch中間表現(IR)(別名PrimsまたはPrims IR)といった構成要素、ならびに TorchInductor、Accelerated Linear Algebra(XLA)、OpenAI のTriton エコシステムといったコンパイラバックエンドを含む、動的な PyTorch コンパイルスタックについて深く掘り下げる。PyTorch コンパイラスタックを図 14-1 に示す。
また、コンパイルパイプラインのデバッグツールや、マルチGPU・マルチノードクラスタでのPyTorchスケーリング用ライブラリについても扱う。さらに、torch.compile の内部動作や、動的形状・可変シーケンス長を効率的に扱う方法を探る。
さらに、PyTorchコンパイラとOpenAI Tritonエコシステムの統合についても検証する。目標は、PyTorchの柔軟なイージー実行開発体験を損なうことなく、PyTorchモデルとアプリケーションの高速化とスケーリングを実現することだ。
第13章で説明したように、PyTorchのtorch.compile はPyTorchコード(およびモデル)をコンパイルし、で大幅な高速化を実現する。ほとんどの場合、次のようにたった1行のコードでこれを実行できる。様々なオプションについては後述する:
compiled_model=torch.compile(model,mode="max-autotune",# ...)
このセクションでは、のPyTorchコンパイルパイプラインのステップを分解する。これには、TorchDynamoによるグラフキャプチャ、AOT Autogradによる前方/後方グラフの統合最適化、PrimTorch IR、TorchInductorによるコード生成が含まれる。このパイプラインは、ターゲットGPUハードウェア向けに最適化されたカーネルを生成する役割を担っており、図14-2に示す通りである。
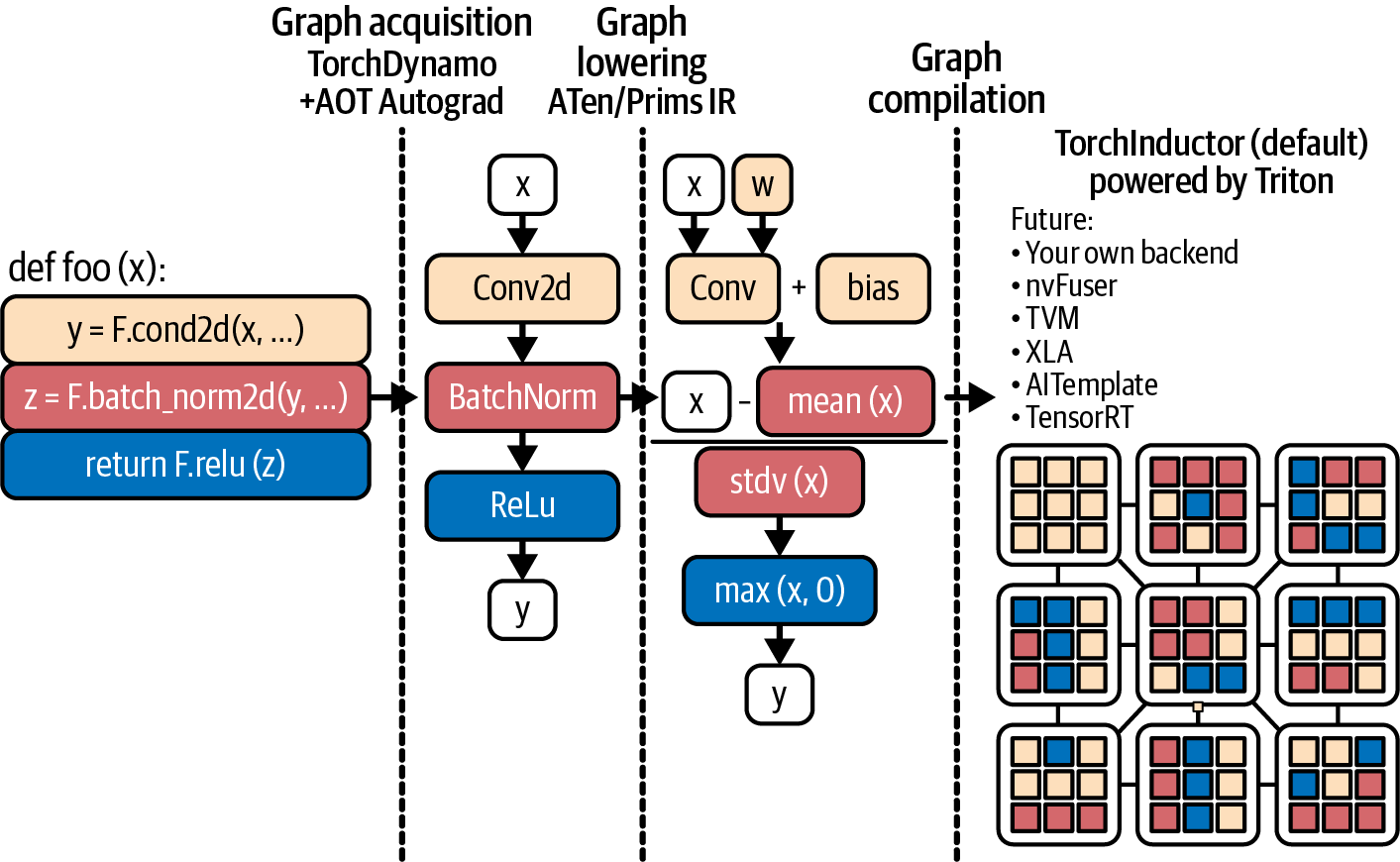
TorchDynamo(または単にDynamo、 ...
Read now
Unlock full access






