November 2025
Intermediate to advanced
1060 pages
18h 47m
Japanese
この作品はAIを使って翻訳されている。ご意見、ご感想をお待ちしている:translation-feedback@oreilly.com
大規模並列性と高いILPで遅延を完全に隠蔽できたとしても、カーネルの性能は依然として、メモリアクセスごとに実行される有用な作業量によって制限される可能性がある。演算密度(オペレーション密度とも呼ばれる)は、メモリから転送されるデータ1バイトあたりに実行される浮動小数点演算の数を、つまりFLOPS/バイトで測定する。
新しいGPU世代は、メモリ帯域幅をはるかに超える演算スループットを実現している。この拡大する差は、演算集約度の向上がこれまで以上に重要であることを意味する。高い演算集約度は、カーネルがフェッチしたバイトごとに多くの計算を行うことを示し、GPUの演算能力を最大限に活用するために不可欠である。
演算密度は、ルーフライン性能モデルにおける主要なメトリックである。 ルーフラインモデルは、カーネル性能(FLOPS/秒)と演算密度(FLOPS/バイト)をプロットする有用な視覚化ツールだ。メモリ帯域幅と演算スループットのハードウェア上限(ルーフ)を示し、カーネルがメモリバウンド(メモリ転送に性能が制限される状態)か、演算バウンド(ALUスループットに性能が制限される状態)かを判断できる。
実際には、Nsight Computeのようなツールでルーフラインチャートを生成できる。このツールにはルーフライン分析ビューが含まれている。これらのツールを使えば、カーネルが初期段階でメモリバウンドか演算バウンドかを検証できる。その後、最適化を進めるにつれてプロファイリングを続け、改善を確認していくのだ。
目標はカーネルを演算リミット領域へ押し上げ、GPUの増大する演算能力を活用することだ。ルーフライン性能モデルはこの目標に向けた最適化を適切に導く。
前章で示したように、ルーフラインチャートでは水平線がハードウェアのピーク演算スループット(屋根)を表し、原点から斜めに伸びる線がメモリ帯域幅によって制限される達成可能なピークスループットを表す。カーネルの算術強度によってx軸上の位置が決まり、図9-1に示すように、その性能はこれらの上限値と比較できる。
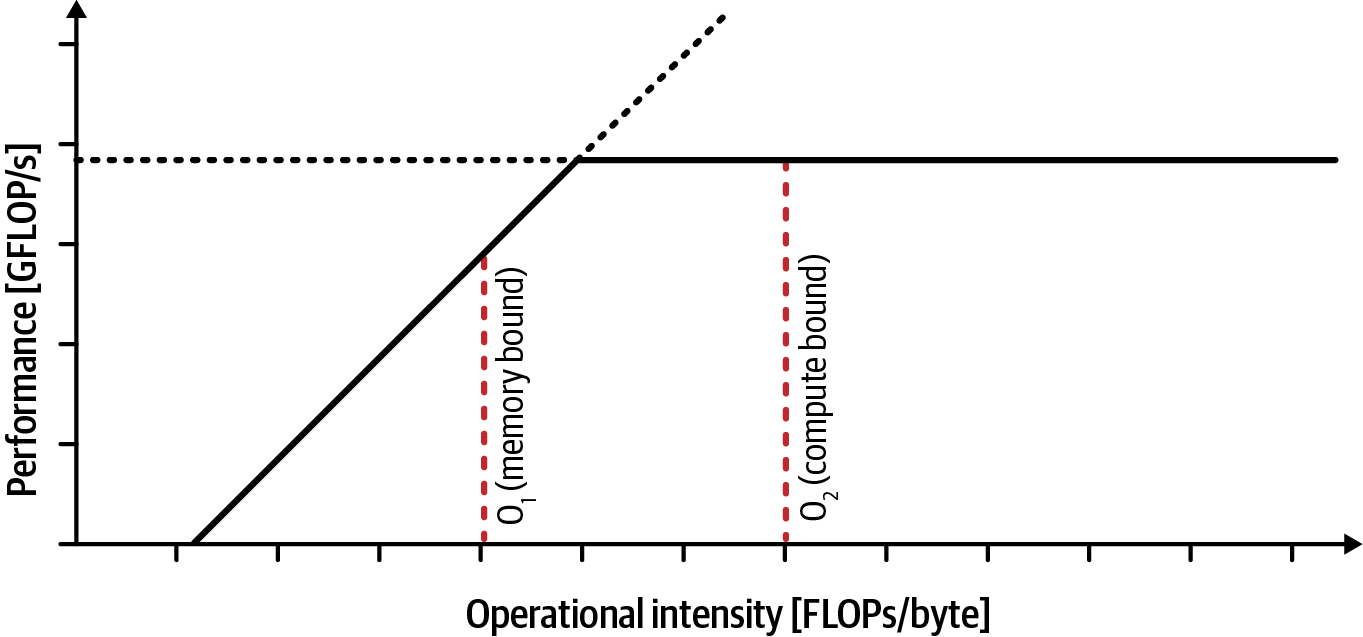
演算強度が低いカーネル、つまりデータ転送量あたりの演算数が少ないカーネルは、メモリに制約される。この場合、GPUは演算よりもデータ待ちに時間を費やすため、カーネルのスピードはハードウェアのメモリ帯域幅によって制限される。
逆に、演算強度が非常に高いカーネル、つまり転送されるバイトあたりのFLOP数が大きいカーネルは、演算処理に制約される。これはALUやテンソルコアがピーク性能に近い状態で稼働しているためだ。この場合、カーネルのメモリ帯域幅使用量は二次的な問題となる。
目標は常に、グローバルメモリとの間で転送されるデータ1バイトあたりの演算量(FLOPs per byte)を増やすことで、可能な限り の演算強度を高めることだ。ループタイリングによるデータの再利用、オンチップL1/共有メモリの活用、中間結果をグローバルメモリに書き込まないよう複数カーネルを1つに融合するといったテクニックで演算強度を向上させられる。 ...
Read now
Unlock full access






