文本数据:扁平化、过滤和分块
|
39
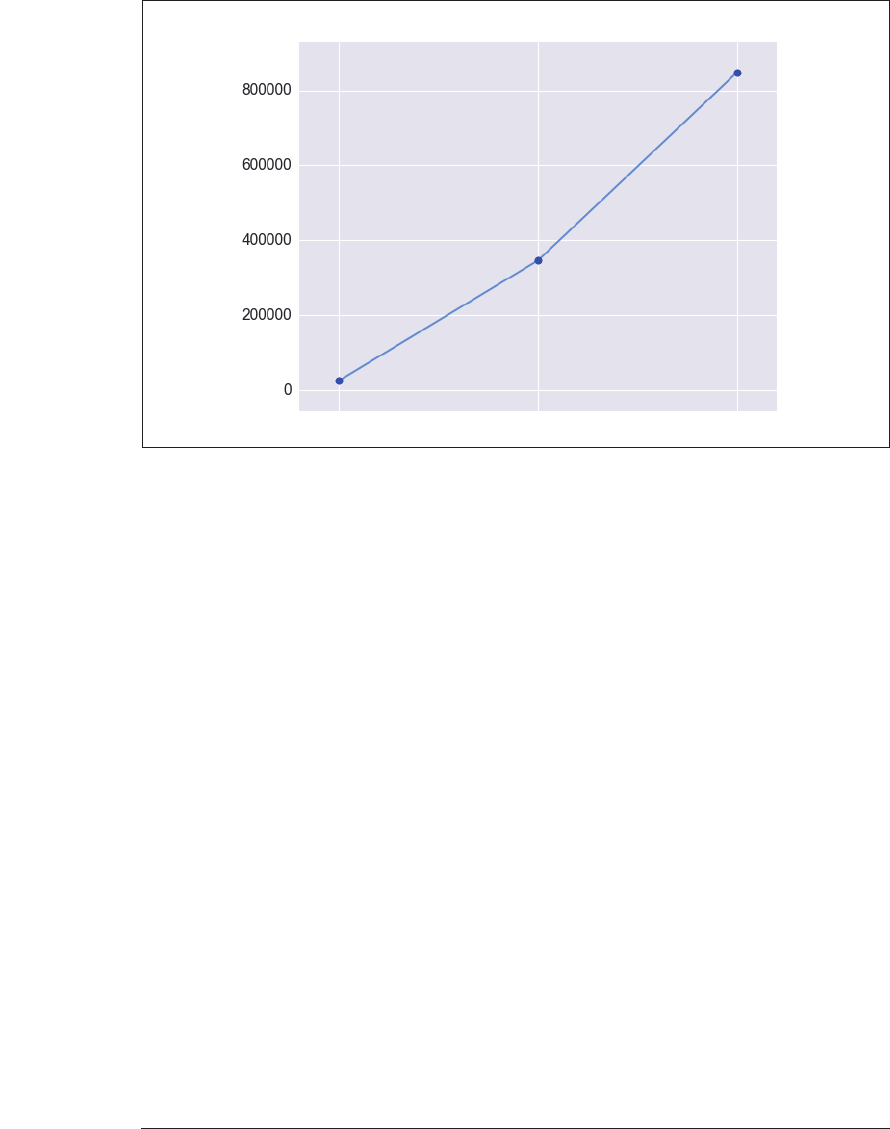
Yelp数据集前10 000条点评中唯一n-gram的数量
一元词 二元词 三元词
图 3-6:Yelp 数据集前 10 000 条点评中唯一
n
-gram 的数量
3.2
使用过滤获取清洁特征
如何通过单词将文本中的信号和噪声准确地区分开呢?使用过滤,那些通过原始分词和计
数来生成单词或
n
-gram
列表的技术将变得更有用。下面要介绍的短语检测可以被看作一种
特别的二元词过滤器。除此之外,我们还会介绍几种其他的过滤方法。
3.2.1
停用词
分类和提取通常不要求对文本进行深入的理解。例如,在句子“
Emma knocked on the
door
”中,单词“
on
”和“
the
”并不能改变这个句子是关于一个人和一扇门这样的事实。
在像分类这样的粗粒度任务中,代词、冠词和介词没有什么价值。但在情感分析中,情况
就完全不同了,它需要对语义进行细粒度的深刻理解。
Python
中通用的
NLP
包
NLTK
中包含了一个由语言学家定义的停用词列表,适用于多种
语言。(你需要先安装
NLTK
,并运行
nltk.download()
来获取完整功能。)在网上也可以
找到各种停用词列表。例如,下面是英语停用词列表中的一些词:
a, about, above, am, an, been, didn't, couldn't, i'd, i'll, itself, let's, myself,
our, they, through, when's, whom, ...
注意,这个列表中包含撇号,而且单词是小写的 ...






