Understanding the datasets
Here, we are using two datasets. The two datasets are as follows:
- The scraped dataset
- The job recommendation challenge dataset
Let's start with the scraped dataset.
Scraped dataset
For this dataset, we have scraped the dummy resume from indeed.com (we are using this data just for learning and research purposes). We will download the resumes of users in PDF format. These will become our dataset. The code for this is given at this GitHub link: https://github.com/jalajthanaki/Basic_job_recommendation_engine/blob/master/indeed_scrap.py.
Take a look at the code given in the following screenshot:
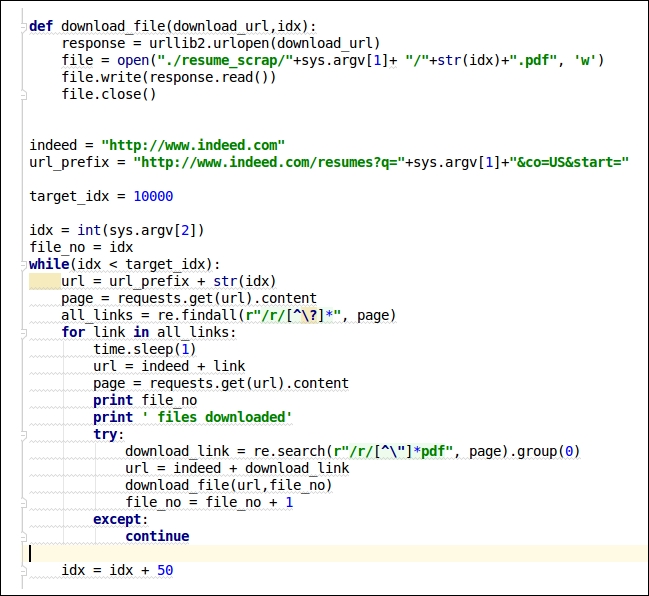
Figure 6.1: Code snippet for scraping ...
Get Machine Learning Solutions now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

