December 2019
Intermediate to advanced
468 pages
14h 28m
English
Transformer-XL introduces a recurrence relationship in the transformer model. During training, the model caches its state for the current segment, and when it processes the next segment, it has access to that cached (but fixed) value, as we can see in the following diagram:
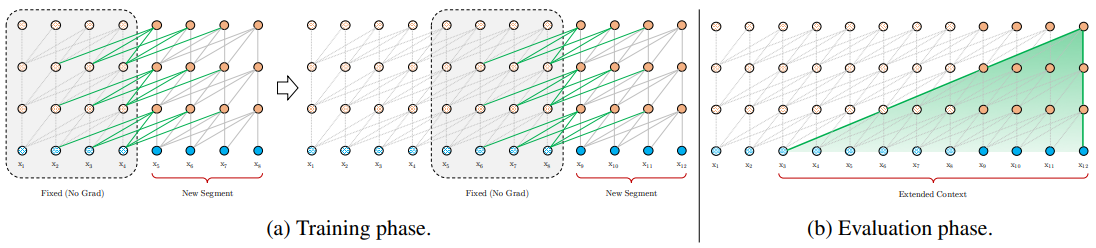
During training, the gradient is not propagated through the cached segment. Let's formalize this concept (we'll use the notation from the paper, which might differ slightly from the previous ...
Read now
Unlock full access






