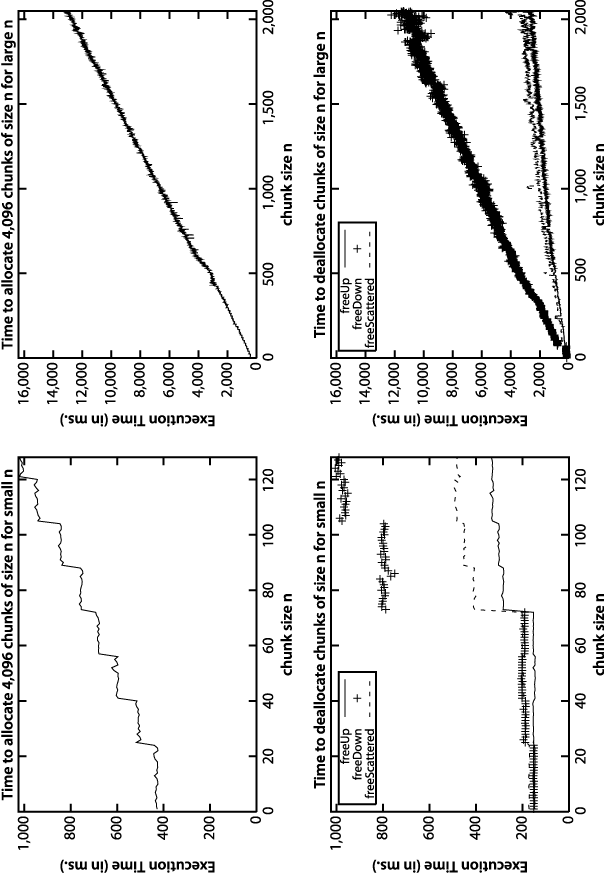
Given the efficiency of using red-black binary trees, is it possible that the malloc() implementation itself is coded to use them? After all, the memory allocation functionality must somehow maintain the set of allocated regions so they can be safely deallocated. Also, note that each of the programs listed previously make allocation requests for 32 bytes. Does the size of the request affect the performance of malloc() and free() requests? To investigate the behavior of malloc(), we ran a set of experiments. First, we timed how long it took to allocate 4,096 chunks of n bytes, with n ranging from 1 to 2,048. Then, we timed how long it took to deallocate the same memory using three strategies:
- freeUp
In the order in which it was allocated; this is identical to ProgramC
- freeDown
In the reverse order in which it was allocated
- freeScattered
In a scattered order that ultimately frees all memory
For each value of n we ran the experiment 100 times and discarded the best and worst performing runs. Figure 1-3 contains the average results of the remaining 98 trials. As one might expect, the performance of the allocation follows a linear trend—as the size of n increases, so does the performance, proportional to n. Surprisingly, the way in which the memory is deallocated changes the performance. freeUp has the best performance, for example, while freeDown executes about four times as slowly.
The empirical evidence does not answer whether malloc() and free() use binary trees (balanced or not!) to store information; without inspecting the source for free(), there is no easy explanation for the different performance based upon the order in which the memory is deallocated.
Showing this example serves two purposes. First, the algorithm(s) behind memory allocation and deallocation are surprisingly complex, often highly tuned based upon the specific capabilities of the operating system (in this case a high-end computer). As we will learn throughout this book, various algorithms have "sweet spots" in which their performance has no equal and designers can take advantage of specific information about a problem to improve performance. Second, we also describe throughout the book different algorithms and explain why one algorithm outperforms another. We return again and again to empirically support these mathematical claims.
Get Algorithms in a Nutshell now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

