Pseudocode Pattern Format
Each algorithm in this book is presented with code examples that show an implementation in a major programming language, such as C, C++, Java, Scheme, and Ruby. For readers who are not familiar with all of these languages, we first introduce each algorithm in pseudocode with a small example showing its execution.
Consider the sample fact sheet shown in Figure 3-1. Each algorithm is named, and its performance is clearly marked for all three behavior cases (best, average, and worst). The upper-right corner of the fact sheet lists a set of concepts used by the algorithm. This is a place that can be used to rapidly see commonalities among different algorithms (e.g., "these two algorithms use a priority queue").
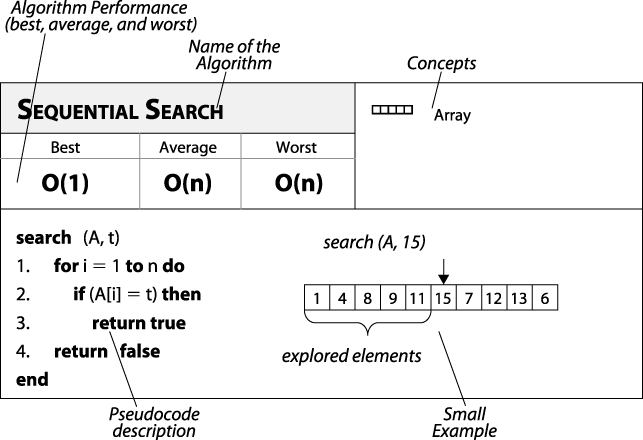
Figure 3-1. Sequential Search fact sheet
The "glyphs" that appear in this region of the fact sheet are depicted in Figure 3-2. Some of these concepts relate to the data structure(s) used by the algorithm (e.g., "Queue"), while others refer to an overall approach to solving the problem (e.g., "Divide and Conquer").
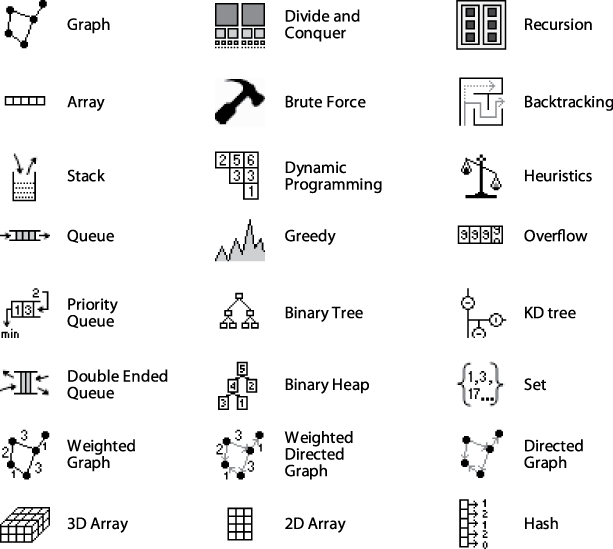
Figure 3-2. Glyphs for identifying algorithmic concepts
The pseudocode description is intentionally kept brief and should fill up no more than 3/4 of a page. Keywords and function names are described in boldface text. All variables are in lowercase ...
Get Algorithms in a Nutshell now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

