January 2018
Beginner to intermediate
284 pages
8h 35m
English
There are two types of attention models: hard attention and soft attention.
In hard attention, each part in a sentence or patch in an image is either used to obtain the context vector or is discarded. In this case, αti represents the probability of the part/patch being used; that is, the probability of indicator St, i = 1. For example, in Xu’s Show, Attend and Tell, the context vector in the hard attention senario is computed as:
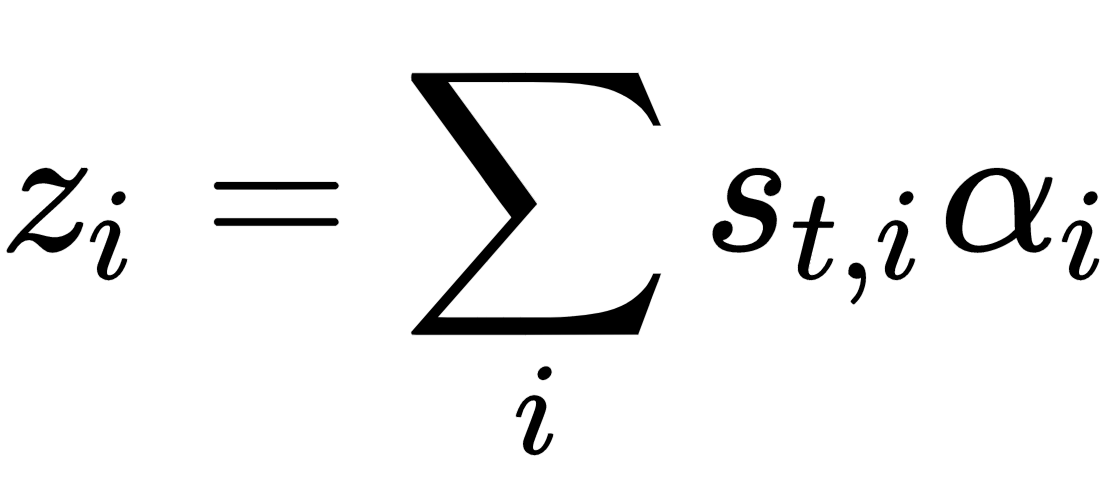
Given the sum-to-one criterion, it can be seen clearly that hard attention selects the element with the highest probability. This is definitely more philosophically ...
Read now
Unlock full access






