January 2018
Beginner to intermediate
284 pages
8h 35m
English
Another interesting application of deep learning is lip reading sentences in the wild. Chung and their co-authors (https://arxiv.org/pdf/1611.05358v1.pdf) in their recent work proposed a method to recognize spoken words by a talking face, with or without audio. The core idea behind the model is a watch-listen-attend-spell network. This network models each output character, yi as a conditional distribution of all previous characters, y<i, input visual sequence of lip images, xv, and input audio sequence, xa, as:
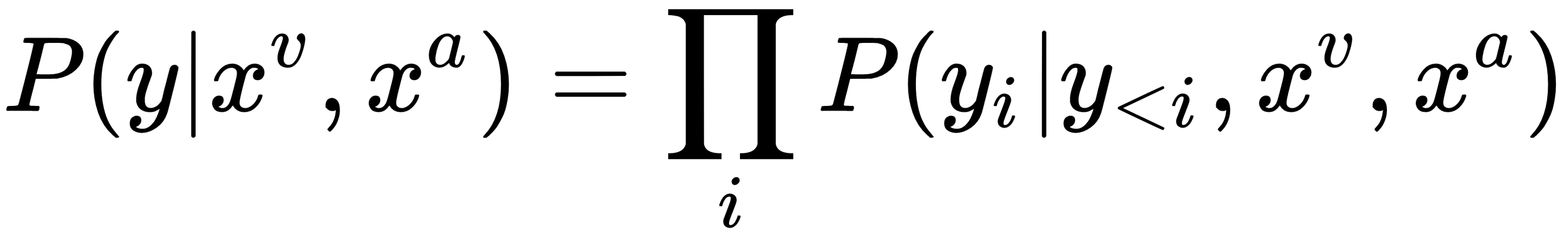
The following figure, Overview of a lip reading application using Watch, Listen, Attend, and Spell architecture, summarizes ...
Read now
Unlock full access






