January 2018
Beginner to intermediate
284 pages
8h 35m
English
The decoder, which often uses an RNN or LSTM, will perform language modeling to transform the image representation to sentences. The input to the very first stage of the decoder (at t = -1) is the output from the encoder. This is to inform the RNN/LSTM about the image content. During the training stage, we use a embeding transform 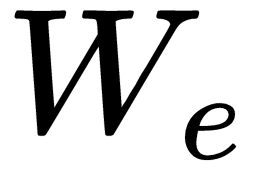 to embed a word at time
to embed a word at time 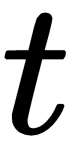 from the ground truth sentence, represented by
from the ground truth sentence, represented by 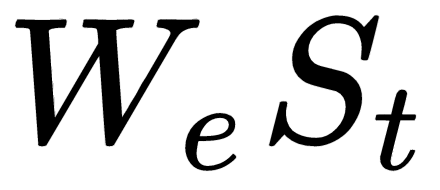 , and feed this embeding to the LSTM ...
, and feed this embeding to the LSTM ...
Read now
Unlock full access






