June 2018
Intermediate to advanced
436 pages
10h 33m
English
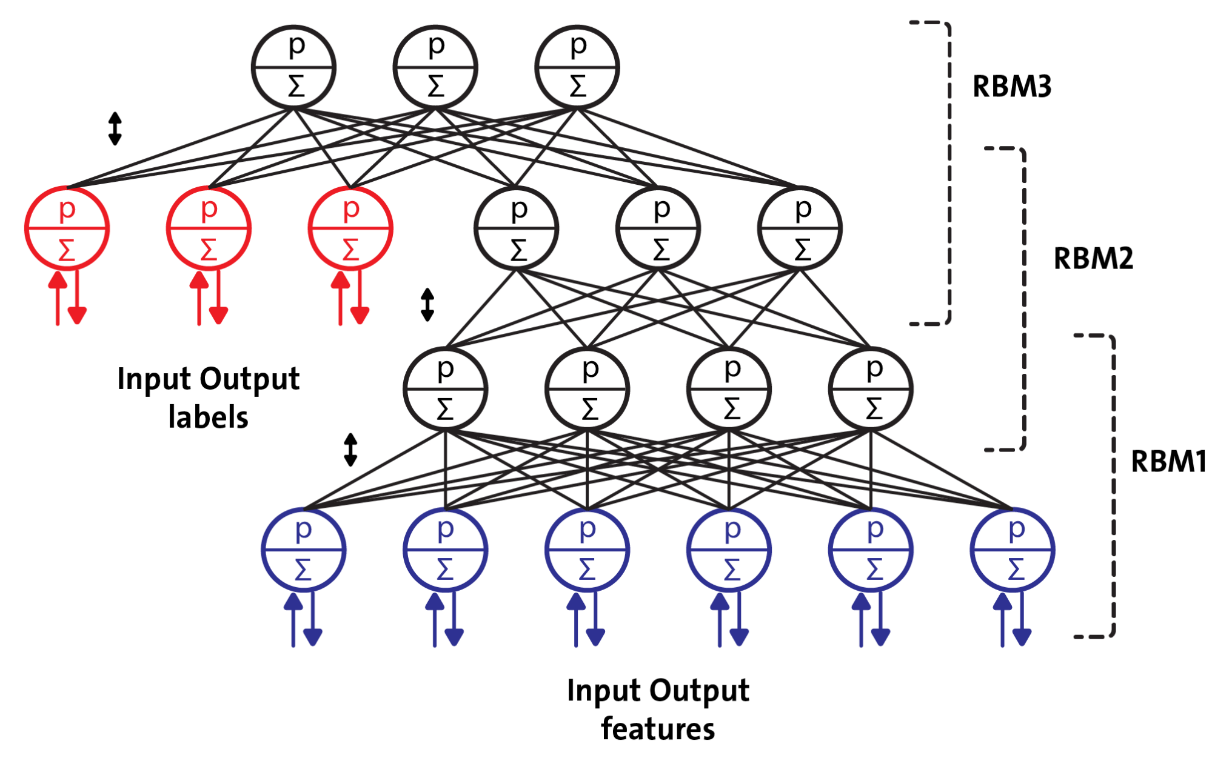
To overcome the overfitting problem in MLPs, the DBN was proposed by Hinton et al. It uses a greedy, layer-by-layer, pre-training algorithm to initialize the network weights through probabilistic generative models.
DBNs are composed of a visible layer and multiple layers—hidden units. The top two layers have undirected, symmetric connections in between and form an associative memory, whereas lower layers receive top-down, directed connections from the preceding layer. The building blocks of a DBN are RBMs, as you can see in the following figure, where several RBMs are stacked one after another to form DBNs: