| Application Features | JavaScript Techniques |
|---|---|
| • Efficient Client-Side Searching | • Using Delimited Strings to Store Multiple Records |
| • Multiple Search Algorithms | • Nested for Loops |
| • Sorted and Portioned Search Results | • Wise Use of document.write( ) |
| • Scalable to Thousands of Records | • Using the Ternary Operator for Iteration |
| • Easily Coded for JavaScript 1.0 Compatibility |
Every site could use a search engine, but why force your server to deal with all those queries? The Client-Side Search Engine allows users to search through your pages completely on the client side. Rather than sending queries to a database or application server, each user downloads the “database” within the requested web pages. This makeshift database is simply a JavaScript array. Each record is kept in one element of the array.
This approach has some significant benefits, chiefly reducing the server’s workload and improving response time. As good as that sounds, keep in mind that this application is restricted by the limitations of the user’s resources, especially processor speed and available memory. Nonetheless, it can be a great utility for your web site. You can find the code for this application in the ch01 folder of the zip file. Figure 1.1 shows the opening interface.
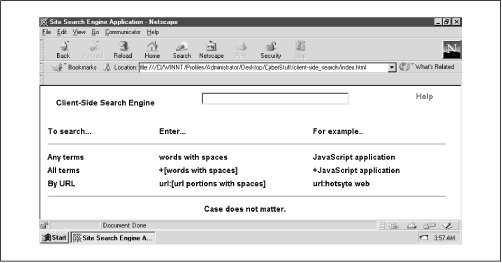
This application comes equipped with two Boolean search methods: AND and OR. You can search by document title and description, or by document URL. User functionality is pretty straightforward. It’s as easy as entering the terms you want to match, then pressing Enter. Here’s the search option breakdown:
Entering terms separated by spaces returns all records containing any of the terms you included (Boolean OR).
Placing a plus sign (+) before your string of query term(s) matches only those records containing all of the terms you enter (Boolean AND).
Entering
url:before a full or partial URL returns those records that match any of the terms in the URL you enter.
Note
Don’t forget your zip file! As noted in the preface, all the code used in this book is available in a zip file on the O’Reilly site. To grab the zip, go to http://www.oreilly.com/catalog/jscook/index.html.
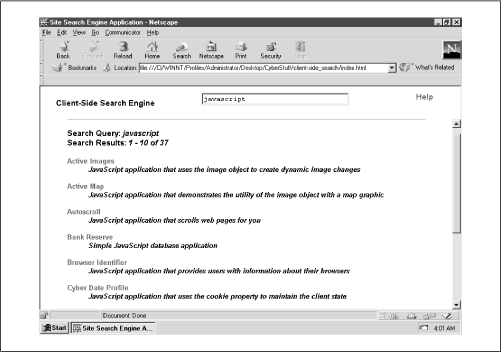
Figure 1.2 shows the results page of a simple search. Notice this particular query uses the default (no prefixes) search method and javascript as the search term. Each search generates on the fly a results page that displays the fruits of the most recent search, followed by a link back to the help page for quick reference.
It’s also nice to be able to search by URL. Figure 1.3 shows a site search using the url: prefix to instruct the engine to search URLs only. In this case the string html is passed, so the engine returns all documents with html in the URL. The document description is still displayed, but the URL comes first. The URL search method is restricted to single-match qualification, just like the default method. That shouldn’t be a problem, though. Not many people will be eager to perform complex search algorithms on your URLs.
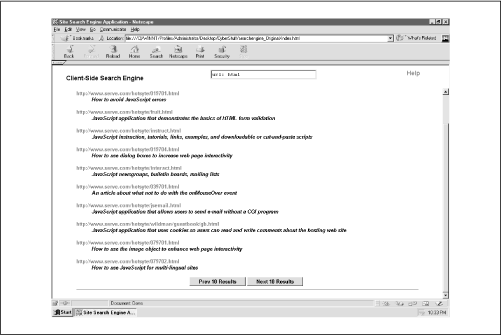
This application can limit the number of results displayed per page and create buttons to view successive or previous pages so that users aren’t buried with mile-long displays of record matches. The number displayed per page is completely up to you, though the default is 10.
> The version of the application discussed here requires a browser that supports JavaScript 1.1. That’s good news for people using Netscape Navigator 3 and 4 and Microsoft Internet Explorer 4 and 5, and bad news for IE 3 users. If you’re intent on backwards compatibility, don’t fret. I’ll show you how you can accommodate IE 3 users (at the price of functionality) later in this chapter in Section 1.5.
All client-side applications depend on the resources of the client machine, a fact that’s especially true here. It’s a safe bet the client will have the resources to run the code, but if you pass the client a huge database (more than about 6,000 or 7,000 records), your performance will begin to degrade, and you’ll eventually choke the machine.
I had no problem using a database of slightly fewer than 10,000 records in MSIE 4 and Navigator 4. Incidentally, the JavaScript source file holding the records was larger than 1 MB. I had anywhere between 24 and 128 MB of RAM on the machine. I tried the same setup with NN 3.0 Gold and got a stack overflow error—just too many records in the array.
On the low end, the JavaScript 1.0 version viewed with MSIE 3.02 on an IBM ThinkPad didn’t allow more than 215 records. Don’t let that low number scare you. The laptop was so outdated you could hear the rat on the exercise wheel powering the CPU. Most users will likely have a better capacity.
Get JavaScript Application Cookbook now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

