11.5. AGGREGATE FACT TABLES
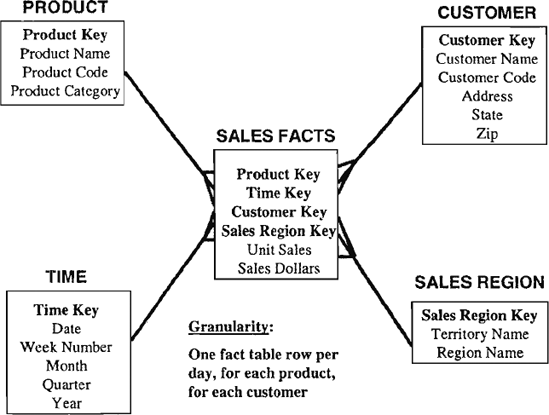
Aggregates are precalculated summaries derived from the most granular fact table. These summaries form a set of separate aggregate fact tables. You may create each aggregate fact table as a specific summarization across any number of dimensions. Let us begin by examining a sample STAR schema. Choose a simple STAR schema with the fact table at the lowest possible level of granularity. Assume there are four dimension tables surrounding this most granular fact table. Figure 11-11 shows the example we want to examine.
When you run a query in an operational system, it produces a result set about a single customer, a single order, a single invoice, a single product, and so on. But, as you know, the queries in a data warehouse environment produce large result sets. These queries retrieve hundreds and thousands of table rows, manipulate the metrics in the fact tables, and then produce the result sets. The manipulation of the fact table metrics may be a simple addition, an addition with some adjustments, a calculation of averages, or even an application of complex arithmetic algorithms.
Let us review a few typical queries against the sample STAR schema shown in Figure 11-11.
Query 1: Total sales for customer number 12345678 during the first week of December 2000 for product Widget-1.
Figure 11-11. STAR schema with most granular fact table.
Query 2: Total sales ...
Get DATA WAREHOUSING FUNDAMENTALS: A Comprehensive Guide for IT Professionals now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

